
目录
Hive基础
Hive介绍
什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
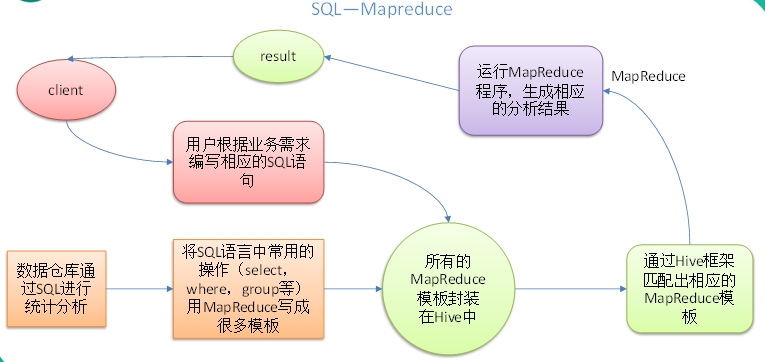
本质是:将HQL转化成MapReduce程序
图示
-
Hive处理的数据存储在HDFS
-
Hive分析数据底层的实现是MapReduce
-
执行程序运行在Yarn上
Hive的优缺点
优点
-
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
-
避免了去写MapReduce,减少开发人员的学习成本。
-
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
-
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
-
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
Hive的HQL表达能力有限
-
迭代式算法无法表达(基于磁盘存储,io很花费时间)。
-
数据挖掘方面不擅长。
Hive的效率比较低
-
Hive自动生成的MapReduce作业,通常情况下不够智能化。
-
Hive调优比较困难,粒度较粗。
Hive架构原理
图解
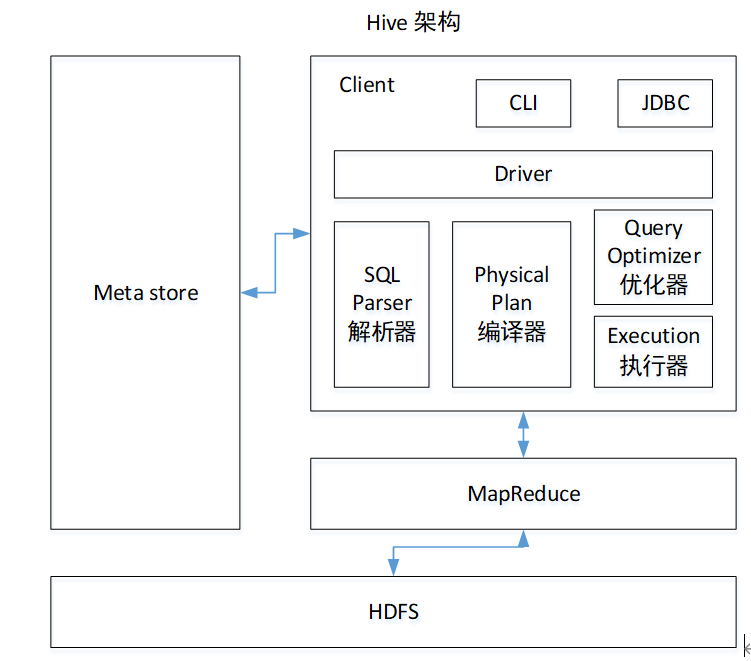
- 用户接口:Client
- CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
- 元数据:Metastore
-
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
-
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- Hadoop
- 使用HDFS进行存储,使用MapReduce进行计算。
- 驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划,也就是将sql语句翻译成mr程序。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
运行机制
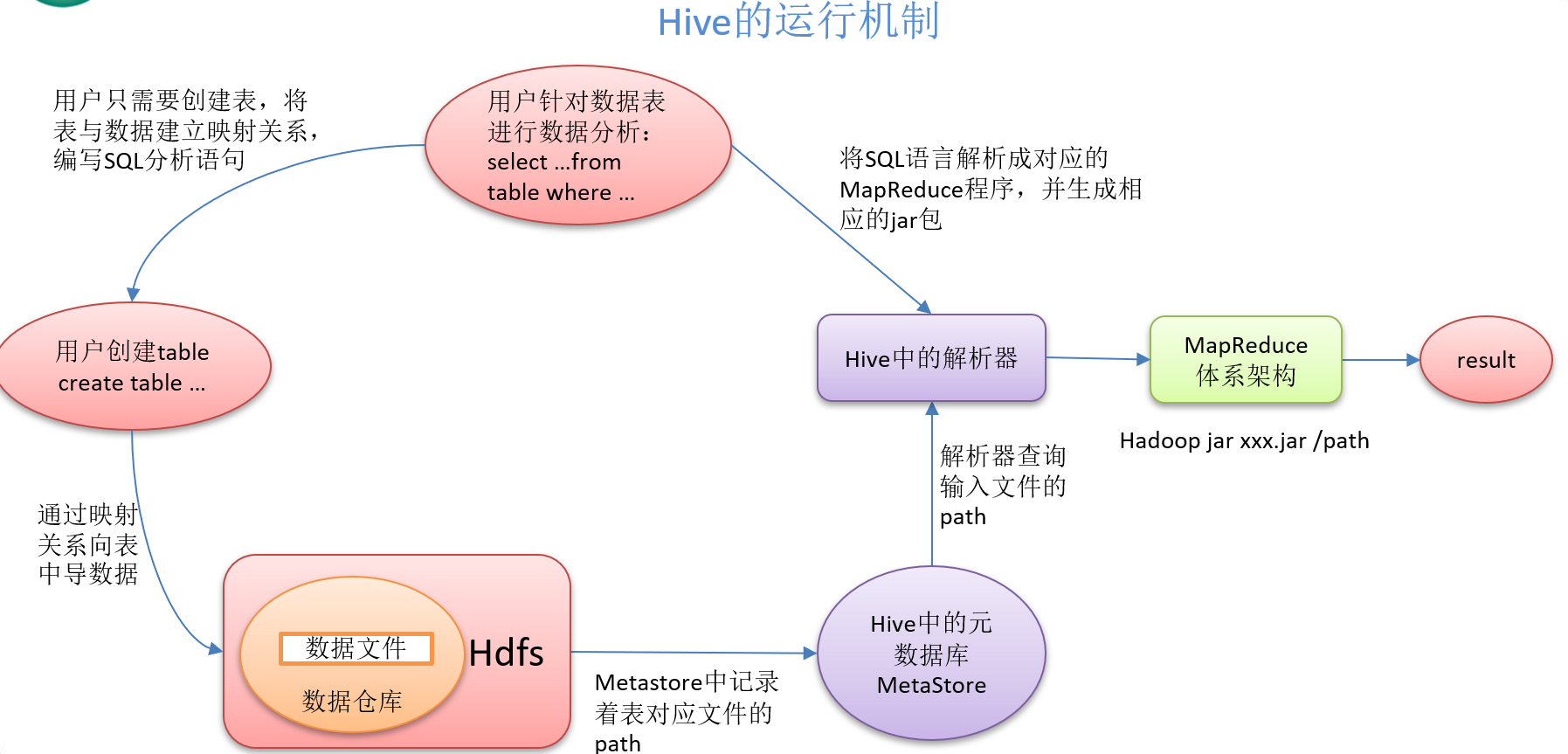
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的(一次写入多次写出)。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle在理论上的扩展能力也只有100台左右。
数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive安装
Hive安装地址
java1.Hive官网地址
http://hive.apache.org/
2.文档查看地址
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3.下载地址
http://archive.apache.org/dist/hive/
4.github地址
https://github.com/apache/hive
Hive安装部署
在安装hive之前
-
把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
-
解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
-
修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
java[root@hadoop01 conf]# mv hive-env.sh.template hive-env.sh
- 配置hive-env.sh文件
java//配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2
//配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf
-
hadoop集群配置
因为hive是基于hadoop,所以在启动hive之前,必须先启动hadoop集群.
java[rzf@hadoop01 hadoop-2.7.2]$ sbin/start-dfs.sh
- 启动hive
java[rzf@hadoop01 hive]$ bin/hive
//查看有那些数据库
hive> show databases;
//打开默认数据库
hive> use default;
//显示default数据库中的表
hive> show tables;
//创建一张表
hive> create table student(id int, name string);
//显示数据库中有几张表
hive> show tables;
//查看表的结构
hive> desc student;
//想表中插入数据
hive> insert into student values(1000,"ss");
//查询数据库
hive> select * from student;
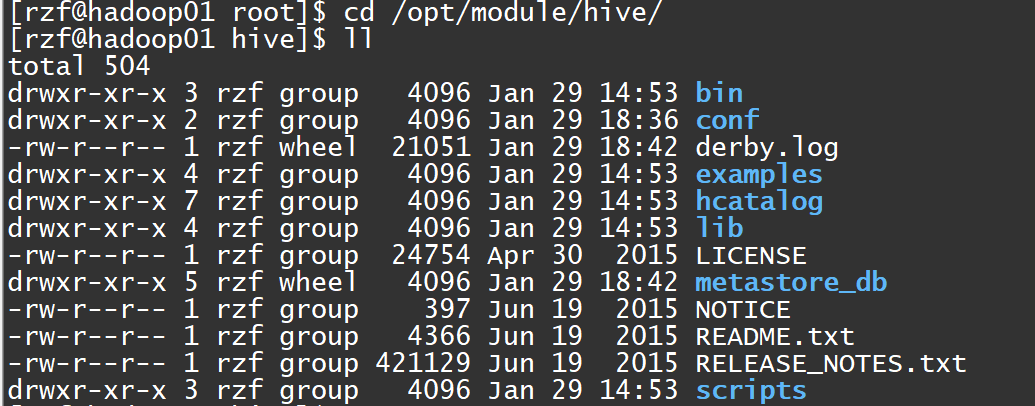
启动开之后,发现hive目录多出了两个目录,derby.log和metastore_db。默认的元数据是存储在derby数据库中的。
默认数据库

- 退出hive
javahive> quit;
Mysql安装
derby存在的问题:同时是能开启一个客户端,所以,我们把元数据存储在Mysql数据库中。
- 查看mysql是否安装,如果安装了,卸载mysql
java[rzf@hadoop01 hive]$ rpm -qa | grep -i mysql
//卸载
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
//--nodeps卸载所有的依赖
//如果采用yun方式安装
##查看opIyNNtU9NOa7p7S
yum list installed mysql*
##卸载,删除方式:yum remove + 【名字】。
yum remove mysql mysql-server mysql-libs compat-mysql51
rm -rf /var/lib/mysql
##可能cannot remove ‘/etc/my.cnf’: No such file or directory
rm /etc/my.cnf
##安装了mysql_devel
yum remove mysql mysql-devel mysql-server mysql-libs compat-mysql51
rm -rf /var/lib/mysql
rm /etc/my.cnf
//如果采用rpm方式安装
##1.查看
rpm -qa | grep -i mysql
##2.卸载,安装的时候带.rpm后缀,卸载时候不带
rpm -e MySQL-server-5.6.27-1.el6.x86_64
rpm -e MySQL-client-5.6.27-1.el6.x86_64
rpm -e MySQL-devel-5.6.27-1.el6.x86_64
##3.删除MySQL服务,此处删除看自己配置的mysql/mysqld
chkconfig --list | grep -i mysql
chkconfig --del mysql
##4.删除分散的MySQL文件
whereis mysql
或者
find / -name mysql
##发现的话移除即可
rm -rf /usr/lib/mysql
rm -rf /var/lib/mysql
rm -rf /usr/share/mysql
rm -rf /root/.mysql_sercret
rm -rf /usr/my.cnf
##查看mysql服务状态
service mysqld status
##关闭mysql服务
service mysqld stop
##启动MySQL
service mysql start
##重启
service mysql restart
##查看root账号的初始密码
cat /root/.mysql_secret
- 解压mysql-libs.zip文件到当前目录
javaunzip mysql-libs.zip
安装mysql服务
java//首先安装mysql服务
[root@hadoop01 mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
A RANDOM PASSWORD HAS BEEN SET FOR THE MySQL root USER !
You will find that password in '/root/.mysql_secret'.
You must change that password on your first connect,
no other statement but 'SET PASSWORD' will be accepted.
See the manual for the semantics of the 'password expired' flag.
Also, the account for the anonymous user has been removed.
In addition, you can run:
/usr/bin/mysql_secure_installation
which will also give you the option of removing the test database.
This is strongly recommended for production servers.
See the manual for more instructions.
Please report any problems at http://bugs.mysql.com/
The latest information about MySQL is available on the web at
http://www.mysql.com
Support MySQL by buying support/licenses at http://shop.mysql.com
WARNING: Found existing config file /usr/my.cnf on the system.
Because this file might be in use, it was not replaced,
but was used in bootstrap (unless you used --defaults-file)
and when you later start the server.
The new default config file was created as /usr/my-new.cnf,
please compare it with your file and take the changes you need.
//查看初始密码
[root@hadoop01 mysql-libs]# cat /root/.mysql_secret
# The random password set for the root user at Fri Jan 29 19:58:56 2021 (local time): sP2Buzy0RMuxWhb5
//查看mysql的状态
[root@hadoop01 mysql-libs]# service mysql status
//启动mysql
[root@hadoop01 mysql-libs]# service mysql start
安装mysql客户端
java//安装客户端
[root@hadoop01 mysql-libs]# rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
//链接客户端
[root@hadoop01 mysql-libs]# mysql -u root -psP2Buzy0RMuxWhb5
//修改密码
mysql> set PASSWORD=PASSWORD('root');
//退出mysql
mysql> exit;
修改无主机登录
也就是在任何主机上面都可以登录数据库
java//显示数据库
mysql>show databases;
//使用mysql数据库
mysql> use mysql;
//展示mysql数据库中的所有表
mysql>show tables;
//展示user表的结构
mysql>desc user;
//查询user表
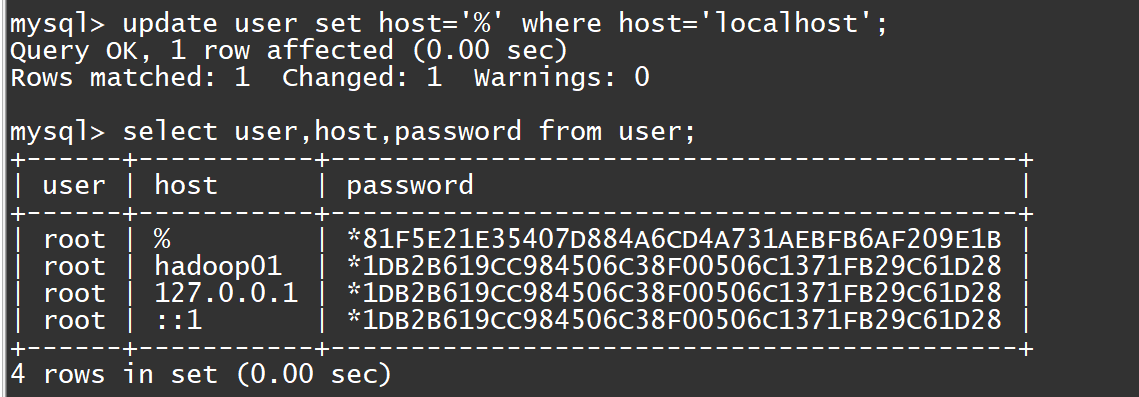
mysql> select user,host,password from user;
//也就是说当前只有在host的四个主机才可以登录mysql数据库,我们要修改在任何主机都可以登录

java//修改user表,把Host表内容修改为%,也就是表示在任何主机上
mysql>update user set host='%' where host='localhost';
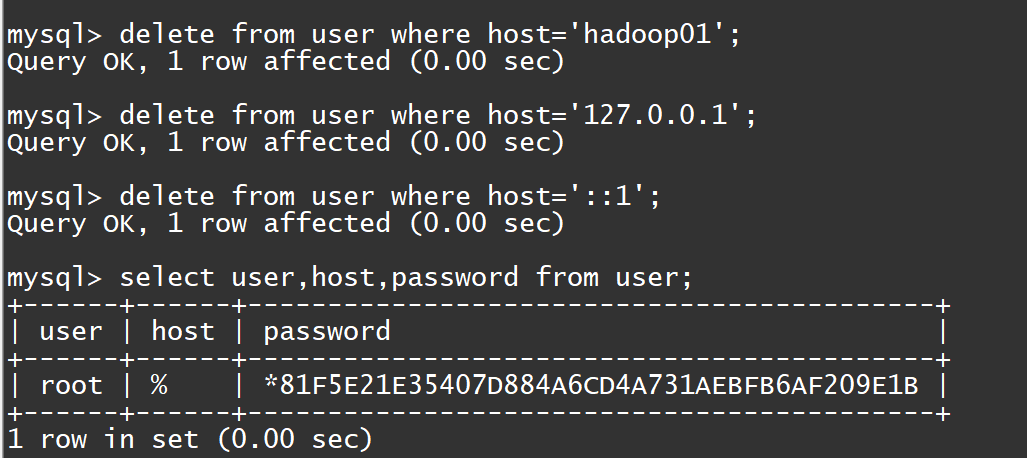
java//删除root用户的其他host
mysql>delete from user where Host='hadoop01';
mysql>delete from user where Host='127.0.0.1';
mysql>delete from user where Host='::1';
//刷新
mysql>flush privileges;
Hive元数据配置到MySql
拷贝驱动
- 在/opt/software/mysql-libs目录下解压mysql-connector-java-5.1.27.tar.gz驱动包
java[rzf@hadoop01 mysql-libs]$ tar -zxvf mysql-connector-java-5.1.27.tar.gz
- 拷贝/opt/software/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/opt/module/hive/lib/
java[rzf@hadoop01 mysql-connector-java-5.1.27]$ cp ./mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
//记住,这里拷贝的是驱动
配置Metastore到MySql
- 在/opt/module/hive/conf目录下创建一个hive-site.xml
java//虽然配置文件下有一个模板配置文件,但是hive并不会加载此文件,所以需要自己创建
[rzf@hadoop01 conf]$ touch hive-site.xml
- 根据官方文档配置参数,拷贝数据到hive-site.xml文件中
java<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
//这里还需要初始化
[rzf@hadoop01 bin]$ schematool -dbType mysql -initSchema
Metastore connection URL: jdbc:mysql://hadoop01:3306/metastore?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 1.2.0
Initialization script hive-schema-1.2.0.mysql.sql
Initialization script completed
schemaTool completed
[rzf@hadoop01 bin]$ pwd
/opt/module/hive/bin
- 配置完毕后,如果启动hive异常,可以重新启动虚拟机。(重启后,别忘了启动hadoop集群)
Hive JDBC访问
启动hiveserver2服务
java[rzf@hadoop01 hive]$ bin/hiveserver2
启动beeline
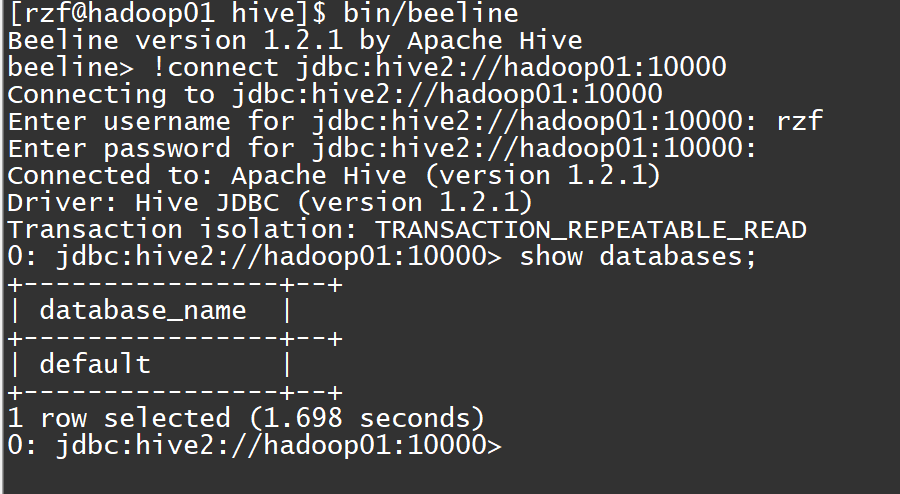
java[rzf@hadoop01 hive]$ bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline>
连接hiveserver2
javabeeline> !connect jdbc:hive2://hadoop100:10000(回车)
Connecting to jdbc:hive2://hadoop01:10000
Enter username for jdbc:hive2://hadoop01:10000: rzf(回车)
Enter password for jdbc:hive2://hadoop01:10000: (直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop01:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| hive_db2 |
+----------------+--+
图示
Hive常用交互命令
查询帮助信息
java[rzf@hadoop01 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line //命令行中直接查询
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
“-e”不进入hive的交互窗口执行sql语句
java[rzf@hadoop01 hive]$ bin/hive -e 'show tables' //可以把命令放入脚本中运行
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties
OK
Time taken: 1.063 seconds
“-f”执行脚本中sql语句
java//也就是把sql写入文件中,执行文件查询
//在/opt/module/datas目录下创建hivef.sql文件
touch hivef.sql
//文件中写入正确的sql语句
select *from student;
//执行sql文件
bin/hive -f /opt/module/datas/hivef.sql
//执行文件中的sql语句并将结果写入文件中
bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt
Hive其他操作命令
退出hive窗口:
javahive(default)>exit;
hive(default)>quit;
在新版的hive中没区别了,在以前的版本是有的:
exit:先隐性提交数据,再退出;
quit:不提交数据,退出;
在hive cli命令窗口中如何查看hdfs文件系统
javahive> dfs -ls /;
在hive cli命令窗口中如何查看本地文件系统
javahive> ! ls /opt/;
查看在hive中输入的所有历史命令
java//进入到当前用户的根目录/root或/home/atguigu
//查看. hivehistory文件

Hive常见属性配置
Hive数据仓库位置配置
-
Default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下。
-
在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
-
修改default数据仓库原始位置(将hive-default.xml.template如下配置信息拷贝到hive-site.xml文件中)。
java<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
//配置同组用户有执行权限
bin/hdfs dfs -chmod g+w /user/hive/warehouse
查询后信息显示配置
在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
java<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
//打印当前数据库
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
重新启动hive,对比配置前后差异。

Hive运行日志信息配置
-
Hive的log默认存放在/tmp/rzf/hive.log目录下(当前用户名下)
-
修改hive的log存放日志到/opt/module/hive/logs
- 修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties
java[rzf@hadoop01 conf]$ mv hive-log4j.properties.template hive-log4j.properties
- 在hive-log4j.properties文件中修改log存放位置
javahive.log.dir=/opt/module/hive/logs
参数配置方式
- 查看当前所有的配置信息
javahive (default)> set;
- 参数的配置三种方式
配置文件方式
-
默认配置文件:hive-default.xml
-
用户自定义配置文件:hive-site.xml
-
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
命令行参数方式(没有启动系统)
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
javabin/hive -hiveconf mapred.reduce.tasks=10;//启动时候设置参数
注意:仅对本次hive启动有效
查看参数设置:
javahive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=-1
参数声明方式(已经进入系统,然后设定参数)
可以在HQL中使用SET关键字设定参数
javahive (default)> set mapred.reduce.tasks=100;
注意:仅对本次hive启动有效。
查看参数设置
javahive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
Hive数据类型
基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | 可以是整数,字符串或者浮点数 | |
| BINARY | 字节数组 |
- 对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
- 如果用户在查询中使用float和double类型进行比较的话,那么hive会自动把float类型转换为double类型,对于其他整数类型来说同理。也就是不同数据之间的比较其实是基于相同数据类型的比较(会自动转换为范围较大的类型)。
- 需要注意的是上面这些数据类型都是对java中接口的实现
加深的类型表示最常用的类型。
hive中并没有键的概念,但是我们可以对数据建立索引。
集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() |
- Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
案例
- 假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
java{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
- 基于上述数据结构,我们在Hive里创建对应的表,并导入数据。
创建本地测试文件test.txt
javasongsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
注意:MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
- Hive上创建测试表test
javacreate table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited
fields terminated by ','//表示字段(属性)之间的分隔符
collection items terminated by '_'//表示集合元素之间的分隔符
map keys terminated by ':'//表示map集合键值对之间分隔符
lines terminated by '\n';//表示行之间的分隔符
结合元素之间的分隔符是一样的。
字段解释:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
map keys terminated by ':' -- MAP中的key与value的分隔符
lines terminated by '\n'; -- 行分隔符
- 加载数据到表中
javahive (default)> load data local inpath '/opt/module/hive/info.txt' into table test;
- 访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT的访问方式
javaselect * from test;

数组的访问
javahive (default)> select friends[0] from test where name = 'songsong';
OK
_c0
bingbing
Map集合的访问
javahive (default)> select children['xiao song'] from test;
OK
_c0
18
NULL
结构体访问
javahive (default)> select address.city from test;
OK
city
beijing
beijing
类型转换
Hive的原子数据类型(基本数据类型)是可以进行隐式转换的,类似于Java的类型转换,例如某表达式使用INT类型,TINYINT会自动转换为INT类型,但是Hive不会进行反向转化,例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。(也就是说范围大的类型不能隐式转换为范围小的类型,但是范围小的类型可以隐式转换为范围大的类型)
隐式类型转换规则如下
-
任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
-
所有整数类型、FLOAT和STRING(特殊情况)类型都可以隐式地转换成DOUBLE。
-
TINYINT、SMALLINT、INT都可以转换为FLOAT。
-
BOOLEAN类型不可以转换为任何其它的类型。
可以使用CAST操作显示进行数据类型转换
例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
读时模式
- 传统的数据库是写时模式,也就是说在数据写入数据库的时候对模式进行检查
- 但是hive不会再数据加载的时候进行验证,而是在查询的时候进行验证,也就是所谓的读时模式。但是如果模式的定义和文件中的数据发生不匹配时候怎么办呢?比如每一行的记录中的字段个数少于模式中定义的字段个数的话,那么用户查询出来的数据将会有很多null值,如果某一些数据类型是数值型,但是hive模式中定义的是字符类型的话,那么 对于这种情况,hive也会返回null值。
- hive对于存储的文件的完整性以及数据内容是否和表模式相一致并没有支配能力,甚至管理表都没有给用户提供这些管理能力
DDL数据定义语言
-
hsql不支持行级数据的插入,更新和删除操作,ihve也不支持事务操作。
-
ddl语言操作的是元数据信息,用于创建,修改,和删除数据库,表,视图,函数和索引等
创建数据库
- 创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
javahive (default)> create database hiveDb
hive (default)> show databases;
OK
database_name
default
hivedb
在hdfs上面多出一个数据库

- 避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
javahive (default)> create database if not exists hiveDb;
- 创建一个数据库,指定数据库在HDFS上存放的位置
javahive (default)> create database hivedb2 location '/hive';
//在根目录下创建一个hivedb2数据库
//添加备注信息
hive (default)> create database hivedb2 comment 'this is a database'location '/hive';

- 在hdfs上面创建文件夹,然后创建数据库指向文件夹
java//创建文件夹
[rzf@hadoop01 hadoop-2.7.2]$ hadoop fs -mkdir -p /database/hive
//创建一个数据库,指向文件夹
hive (hiveDb2)> create database hiveDb3 location '/database/hive';
-
现在此路径下的文件夹就是hiveDb3数据库存储文件的位置。
-
hive自带的默认数据库指向的就是/user/hive/warehouse路径下的文件夹。
-
数据库的名字和hdfs上面的对应文件夹的名字可以不一样,比如3处的文件夹。
查询数据库
显示数据库
javahive (hiveDb2)> show databases;
过滤显示查询的数据库
javahive (hiveDb2)> show databases like 'hiveDb*';
OK
database_name
hivedb
hivedb2
hivedb3
查看数据库详情
java//显示数据库结构信息
hive (hiveDb2)> desc database hiveDb2;
OK
db_name comment location owner_name owner_type parameters
hivedb2 hdfs://hadoop01:9000/hive rzf USER
// 显示数据库详细信息,extended formatted
hive (hiveDb2)> desc database extended hiveDb2;
OK
db_name comment location owner_name owner_type parameters
hivedb2 hdfs://hadoop01:9000/hive rzf USER
Time taken: 0.017 seconds, Fetched: 1 row(s)
切换数据库
javahive (hiveDb2)> use hiveDb3;
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。**数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。**只能修改附加信息(也就是添加的属性可以修改)。
javahive (hiveDb3)> alter database hiveDb2 set dbproperties('createtime'='20200105');
//查看数据库信息
hive (hiveDb3)> desc database extended hiveDb2;
OK
db_name comment location owner_name owner_type parameters
hivedb2 hdfs://hadoop01:9000/hive rzf USER {createtime=20200105}
删除数据库
java//删除空数据库,这种方法如果数据库非空的话,无法删除
hive (hiveDb3)> drop database hiveDb2;
- 如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
javahive (hiveDb3)> drop database if exists hiveDb2;
- 如果数据库不为空,可以采用cascade命令,强制删除
javahive (hiveDb3)> drop database hiveDb3 cascade;
创建表
注意:如果使用if not exists语句的话,在创建数据苦衷已经存在相同表名的表时候,如果创建的表的模式和已存在的表的模式不同的话,那么Hive会忽略当前创建表的模式,不会做覆盖操作。
创建表语法
javaCREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name //创建表
[(col_name data_type [COMMENT col_comment], ...)] //为列添加注释
[COMMENT table_comment] //为表添加注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //创建分区表
[CLUSTERED BY (col_name, col_name, ...) //创建分桶表
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] //排序操作
[ROW FORMAT row_format] //分隔符
[STORED AS file_format]
[LOCATION hdfs_path]
//创建表结构,也就是拷贝表的模式,也可以定义存储位置,但是注意一点,拷贝是连元表的属性什么的全部拷贝,不可以重新定义
create table if not exists temp like table_name location
create table temp like table_name;
//显示表的属性信息
show tblproperties table_name
//查看表的详细信息
describe extended table_name -- 在这里extended也可以使用formatted代替
//如果只是想查看某一列的类型信息
describe table_name.col_name
字段解释说明
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
- COMMENT:为表和列添加注释。
- PARTITIONED BY创建分区表
- CLUSTERED BY创建分桶表
- SORTED BY不常用
- 分隔符:用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
javaROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
- STORED AS指定存储文件类型
- 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
- 如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- LOCATION :指定表在HDFS上的存储位置。
- LIKE允许用户复制现有的表结构,但是不复制数据。
管理表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
普通表
java//创建表
create table if not exists student(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile location '/user/hive/warehouse/student';
//根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student1 as select id, name from student;
//根据已经存在的表结构创建表,仅仅创建表的结构,并不会复制表中的数据
create table if not exists student2 like student;
//查询表的类型
hive (default)> desc formatted student;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
Owner: rzf
CreateTime: Sun Jan 31 17:40:00 CST 2021
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop01:9000/user/hive/warehouse/student
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE false
numFiles 0
numRows -1
rawDataSize -1
totalSize 0
transient_lastDdlTime 1612086000
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
外部表
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
管理表和外部表的应用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
案例
java//分别创建部门和员工外部表,并向表中导入数据。
//创建部门表
create external table if not exists default.dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
//创建员工表
create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
//查看表
hive (default)> show tables;
OK
tab_name
dept
emp
//加载数据到表中,从本地磁盘加载数据
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table dept;
hive (default)> load data local inpath '/opt/module/data/emp.txt' into table emp;
//查看表格式化数据
hive (default)> select * from dept;
//可以发现表的类型是外部表
表信息
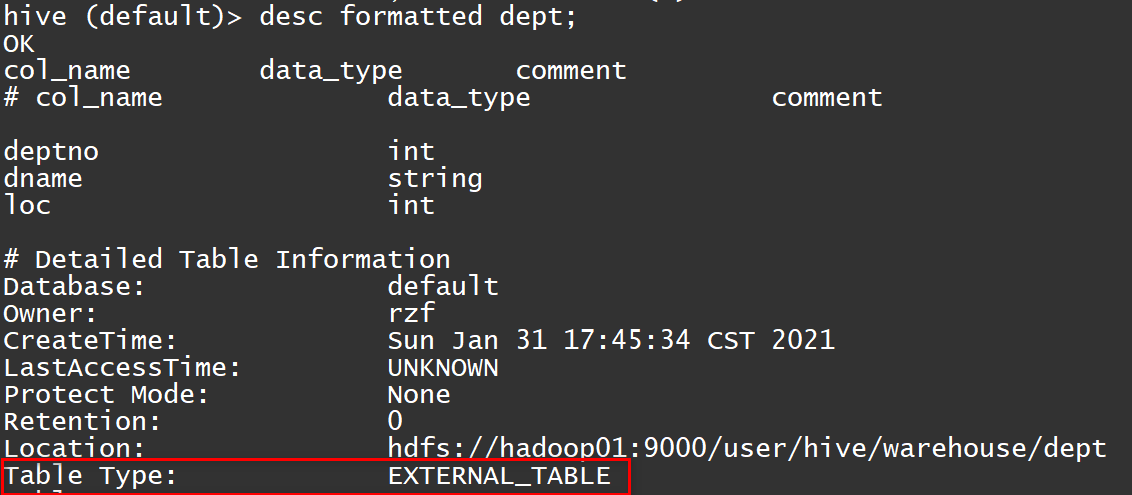
数据的存储

可以看到,对应表中的数据存储在对应的数据库下面。下面我们删除dept这张表。
javahive (default)> drop table dept;
hive (default)> show tables;
OK
tab_name
emp
可以发现,在hdfs上面的数据依然存在,也就是说对于管理表或者说是内部表,如果删除表的话,不仅把元数据删除,对应的表中的数据也会删除,但是对于外部表,删除的仅仅是元数据,也就是表的信息,但是在hdfs上面表目录下面的数据并不会真正删除。
如果现在重新创建dept表的话,然后进行查询,可以查询成功,查询的时候,会先到mysql数据库中查询·表的元数据信息,然后在到hdfs上面对应的目录查看是否有数据,有的话就直接返回。查询数据是根据hdfs上面的文件夹进行的,只要有对应数据库的文件夹,并且文件夹下面的数据的格式正确,就可以查询成功。查询不到数据的只可能是两种情况,元数据没有或者hdfs上面的数据没了。
管理表与外部表的互相转换
java//查询表的类型
hive (default)> desc formatted dept;
Table Type: EXTERNAL_TABLE
//修改为内部表
alter table dept set tblproperties('EXTERNAL'='false');
//查看表类型
hive (default)> desc formatted dept;
Table Type: MANAGED_TABLE
//如果再次又该为外部表
alter table dept set tblproperties('EXTERNAL'='true');
//复制一个外部表
create external table if not exists table_name like copy_name location 'path'
//这里需要注意一点:如果省略掉external关键字的话,那么如果原表是管理表,那么复制出来的表也是管理表,如果原表是外部表的话,那么复制出来的表也是外部表但是如果语句中包含有external关键字的话,而且原表是管理表,那么生成的表是外部表,location语句是可选的
注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。(因为where子句可以减少查询的数据量,经过一次赛选)
创建分区表
sqlhive (default)> create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
-- 查看一个表的所有分区
show partitions table_name
show partitions table_name partition(country='us')
加载数据到分区表中
java-- 加载数据到表中的时候创建分区
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='202009');
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='202008');
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='202007');
可以看到分区表下面根据时间分成文件夹存放数据
查询数据
javahive (default)> select * from dept_partition;
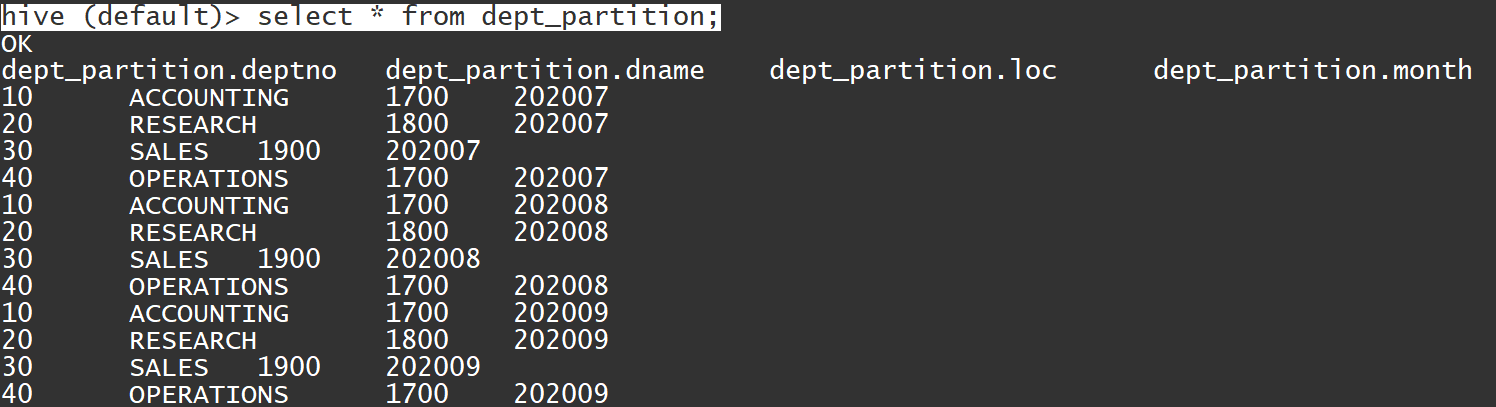
可以查询到各个分区下面的数据,并且显示分区的时间。
分区字段也可以放在where子句中查询
javahive (default)> select * from dept_partition where month='202009';

我们可以在metastore数据库中的partition表中查看根据分区字段创建的表

注意:分区就是根据某一个字段,把数据分文件夹存放,这样操作可以避免在查询的时候扫描所有的数据,提高查询效率。
分区的元数据信息存储在mysql数据库中,在查询的时候,先去mysql数据库查找元数据信息,然后把分区字段拼接到where子句后面进行条件查找。最终在hdfs上面只会定位到一个文件夹,不会对所有的分区文件夹进行查找扫描。
多分区查询数据
javahive (default)> select * from dept_partition where month='202008'
> union
> select * from dept_partition where month='202007';
增加分区
java-- 给表增加一个分区
hive (default)> alter table dept_partition add partition(month='202006');
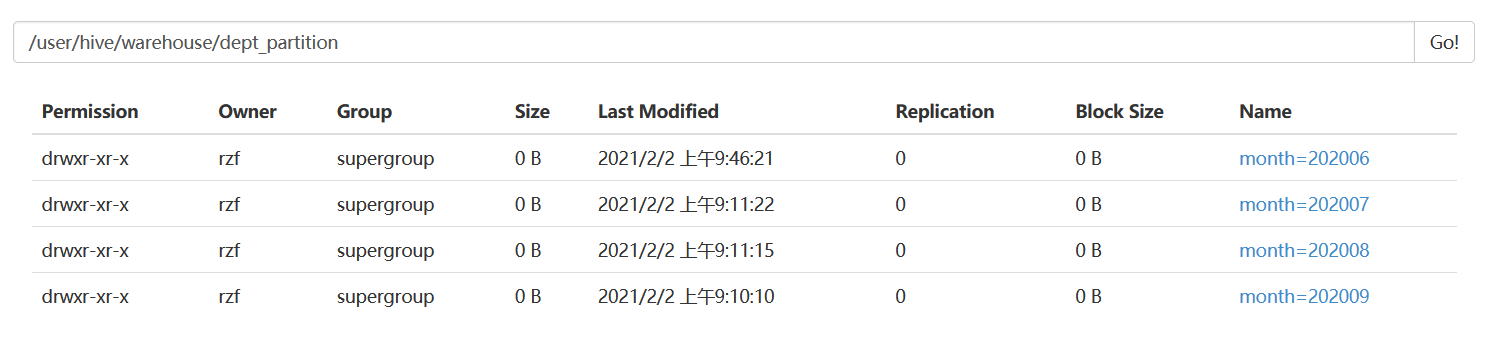
同时增加多个分区
javahive (default)> alter table dept_partition add partition(month='202004') partition(month='202005');
//分区之间使用空格
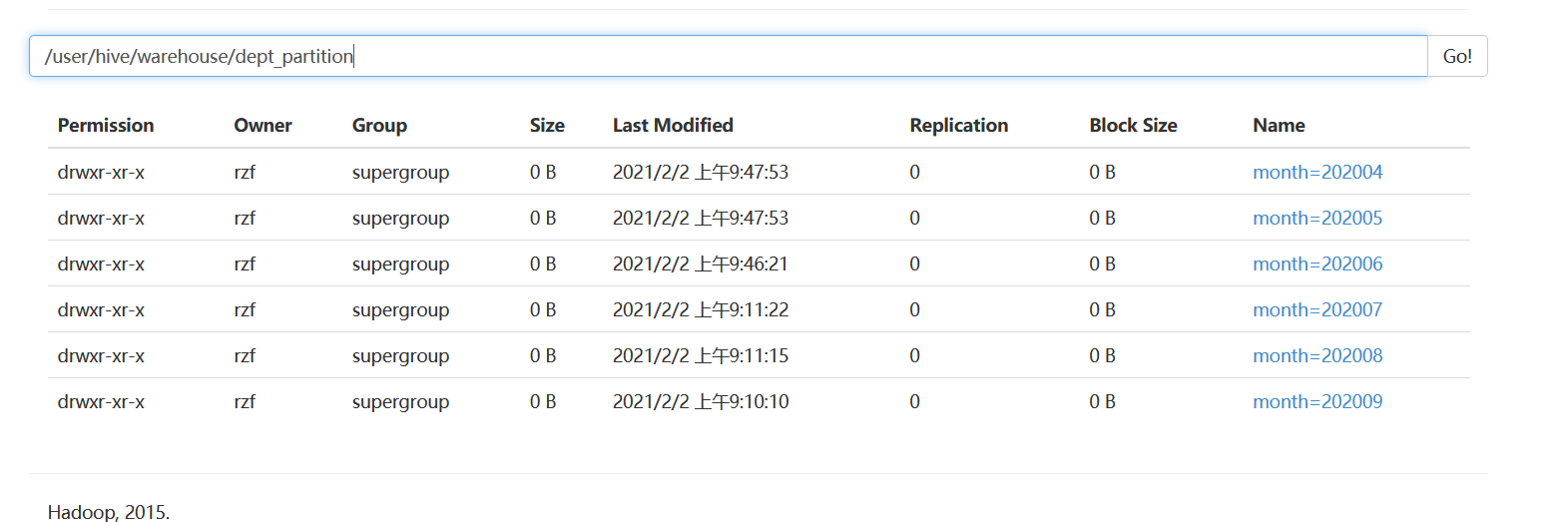
如果把数据使用hadoop fs -put 命令上传到hdfs的某一个分区下面,此时也可以进行数据查询,** **
删除分区
javahive (default)> alter table dept_partition drop partition (month='202005');
同时删除多个分区
javahive (default)> alter table dept_partition drop partition (month='202006'),partition(month='202004');
//分区之间使用,分开
Dropped the partition month=202004
Dropped the partition month=202006
查看分区表有多少分区
javahive (default)> show partitions dept_partition;
OK
partition
month=202007
month=202008
month=202009
查看分区表结构
javahive (default)> desc formatted dept_partition;
OK
col_name data_type comment
# col_name data_type comment
deptno int
dname string
loc string
# Partition Information
# col_name data_type comment
month string //显示分区字段
# Detailed Table Information
Database: default
Owner: rzf
CreateTime: Tue Feb 02 09:07:10 CST 2021
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop01:9000/user/hive/warehouse/dept_partition
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1612228030
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
分区表注意事项
创建二级分区表
javacreate table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
正常的加载数据
java//加载到二级分区目录
load data local inpath '/opt/module/data/dept.txt' into table
default.dept_partition2 partition(month='202009', day='01');

查询分区数据
javahive (default)> select * from dept_partition2 where month='202009' and day='01';
OK
dept_partition2.deptno dept_partition2.dname dept_partition2.loc dept_partition2.month dept_partition2.day
10 ACCOUNTING 1700 202009 01
20 RESEARCH 1800 202009 01
30 SALES 1900 202009 01
40 OPERATIONS 1700 202009 01
也有外部分区表,和管理分区表一样,区别是删除外部分区表时,数据不会被删除,只会删除表的模式。
为外部分区表指定分区使用alter table add partition方法增加分区
把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
方式一:上传数据后修复
上传数据
java//创建目录
[rzf@hadoop01 hadoop-2.7.2]$ hadoop fs -mkdir -p /user/hive/warehouse/dept_partition/month=202006;
//上传数据
[rzf@hadoop01 hadoop-2.7.2]$ hadoop fs -put /opt/module/data/dept.txt /user/hive/warehouse/dept_partition/month=202006;

查询数据(查询不到刚上传的数据)
javahive (default)> select * from dept_partition where month='202006';
虽然在202006目录下有数据,但是在mysql数据库中并没有元数据信息,所以查不到数据信息。
方式一
现在执行修复命令
javahive (default)> msck repair table dept_partition;
OK
Partitions not in metastore: dept_partition:month=202006
Repair: Added partition to metastore dept_partition:month=202006
Time taken: 0.37 seconds, Fetched: 2 row(s)
//校验会重新查看hdfs分区对应的目录在mysql数据库中是否有元数据信息
然后重新查询数据可以查询到。
执行添加分区
javaalter table dept_partition2 add partition(month='202006', day='11');
使用添加分区的方式,会自动把元数据存储到mysql数据库中。
创建文件夹后load数据到分区
javaload data local inpath '/opt/module/data/dept.txt' into table
dept_partition2 partition(month='202006',day='10');
load操作会执行两个操作,第一是把元数据信息添加到Mysql数据库中,第二个操作是把数据加载到hdfs对应的目录下面。
增加分区并且指定分区的路径
sqlalter table table_name add if not exists partition(year=2011,month=2,day=3)location '/logs/2011/02/03'
--修改某一个分区的路径,此命令不会将数据从旧路径转移走,也不会删除就的数据
alter table table_name partition(year=2011,month=2,day=3)set location 'new path '
修改表
重命名表
javahive (default)> alter table student rename to stu;
增加、修改和删除表分区
详见分区章节
增加/修改/替换列信息
更新列
java-- 表是将字段移动到col1字段之后,如果想移动到第一个字段,可以使用first代替afetr col1即可
//此语句修改的是元数据信息
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] after col1
增加和替换列
java//可以把replace理解为删除表中原有的模式,重新建立新的字段类型
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
案例演示
java//增加一列
hive (default)> alter table stu add columns (age int);
hive (default)> desc stu;
OK
col_name data_type comment
id int
name string
age int
//修改列的名字和类型
//修改id列为stuNum,类型是string
hive (default)> alter table stu change column id stuNum string;
hive (default)> desc stu;
OK
col_name data_type comment
stunum string
name string
age int
//替换列
hive (default)> alter table stu replace columns(id int);
hive (default)> desc stu;
OK
col_name data_type comment
id int
//也就是说,替换的话会替换掉所有的列
//也可以一次替换多个列
hive (default)> alter table stu replace columns(id int,name string);
replace是对整张表进行替换,修改单个列的话使用change,如果使用replace改变表的字段个数,表的字段个数小于数据的字段个数,那么查询的时候,只能查询到改变字段后的字段所对应的数据。
DML数据操作
对数据进行增删改查操作。
数据导入
也就是把数据从hdfs上面导入到hive表中
向表中装载数据(Load)
语法
sqlhive> load data [local] inpath '/opt/module/datas/student.txt' overwrite | into table student [partition (partcol1=val1,…)];
- load data:表示加载数据
- local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
- inpath:表示加载数据的路径
- overwrite:表示覆盖表中已有数据,否则表示追加
- into table:表示加载到哪张表
- student:表示具体的表
- partition:表示上传到指定分区
案例演示
java//创建一张表
hive (default)> create table temp(id int,loc string,price int)row format delimited fields terminated by '\t';
//加载本地文件到hive
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table temp;
//覆盖数据
hive (default)> load data local inpath '/opt/module/data/dept.txt' overwrite into table temp;
加载HDFS文件到hive中
java//创建文件夹
[rzf@hadoop01 data]$ hadoop fs -mkdir -p /data
//上传文件到hdfs
[rzf@hadoop01 data]$ hadoop fs -put /opt/module/data/dept.txt /data/
//加载HDFS上数据,加载后,hdfs上的数据会消失
hive (default)> load data inpath '/data/dept.txt' into table temp;
//加载数据覆盖表中已有的数据
hive (default)> load data inpath '/data/dept.txt' overwrite into table temp;
通过查询语句向表中插入数据(Insert)
有追加和覆盖两种模式
- 复制一张表
javahive (default)> create table student(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';
- 向表中插入数据(基本插入数据,也就是追加数据)
javahive (default)> insert into table student partition(month='201709') values(1,'wangwu');
- 基本模式插入(根据单张表查询结果)(会覆盖表中原来的数据)
java//覆盖操作 注意没有into语句
insert overwrite table student partition(month='201708')
select id, name from student where month='201709';
- 多插入模式(根据多张表查询结果)
javahive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
查询语句中创建表并加载数据(As Select)
根据查询结果创建表(查询的结果会添加到新创建的表中)
javacreate table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2'
as select id, name from student;
创建表时通过Location指定加载数据路径
java//在hdfs上指定的位置创建一张表
create table stu(name string,age int) row format delimited fields terminated by '\t' location '/user/hive/warehouse/stu';
//加载本地文件到创建的表的路径下面
bin/hadoop fs -put info.txt '/user/hive/warehouse/stu'
//查询数据
select * from stu;
Import数据到指定Hive表中
注意:先用export导出后,再将数据导入。
javahive (default)> import table sttudent partition(month='201709') from '/user/hive/warehouse/stu';
//把数据从stu中导进student表中
数据导出
也就是说数据现在在hive表中,我们需要导出到hdfs上面。
Insert导出
将查询的结果导出到本地
java//将stu表中的数据导出到本地目录下面,但是此时并不会影响hdfs上面stu表中的数据
//但是导出的数据没有分隔符
insert overwrite local directory '/opt/module/hadoop-2.7.2/fi' select * from stu;
将查询的结果格式化导出到本地
javainsert overwrite local directory '/opt/module/hadoop-2.7.2/file' row format delimited fields terminated by '\t' select * from stu;
//也可以使用覆盖的方式,直接覆盖fi目录下的文件
insert overwrite local directory '/opt/module/hadoop-2.7.2/fi' row format delimited fields terminated by '\t' select * from stu;
将查询的结果导出到HDFS上(没有local)
javainsert overwrite directory '/rzf/file/' row format delimited fields terminated by '\t' select * from stu;
//查询数据
bin/hadoop fs -cat /rzf/file/0*
Hadoop命令导出到本地
javahive (default)> dfs -get /user/hive/warehouse/student/month=201709/000000_0
/opt/module/datas/export/student3.txt;
Hive Shell 命令导出
基本语法:(hive -f/-e 执行语句或者脚本 >file):>是Linux写入文件的操作
javabin/hive -e 'select * from default.student;' >
/opt/module/datas/export/student4.txt;
Export导出到HDFS上
java//先把表中的数据导出到hdfs路径上,把表stu中的数据导出到export目录下面
hive (default)> export table stu to 'export';
//现在使用import命令把export目录下的数据导入到其他的表中
//注意,加载到temp表中,表的元数据要和export文件下的表的元数据相同,也就是列相同
import table temp from '/export';
Sqoop导出
清除表中数据(Truncate)
清空表,并不会删除元数据,只是删除的是数据,删除hdfs上面的数据,如果是外部表,不会删除数据,清空表删除的是内部表的数据。
注意:Truncate只能删除管理表,不能删除外部表中数据
javatruncate table student;
查询
java//查询语句
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
基本查询(Select…From)
全表和特定列查询
全表查询
javaselect * from stu;
选择特定列查询
javaselect name from stu;
注意
-
SQL 语言大小写不敏感。
-
SQL 可以写在一行或者多行
-
关键字不能被缩写也不能分行
-
各子句一般要分行写。
-
使用缩进提高语句的可读性。
列命名
-
重命名一个列。
-
便于计算。
-
紧跟列名,也可以在列名和别名之间加入关键字‘AS’。
算术运算符
| 运算符 | 描述 |
|---|---|
| A+B | A和B相加 |
| A-B | A减去B |
| A*B | A和B相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
常用函数
- 求总行数(count)
sqlselect count(*) from stu;
- 求工资的最大值(max)
sqlselect max(sal) max_sal from emp;
- 求工资的最小值(min)
sqlselect min(sal) min_sal from emp;
- 求工资的总和(sum)
sqlselect sum(sal) sum_sal from emp;
- 求工资的平均值(avg)
sqlselect avg(sal) avg_sal from emp;
Limit语句
典型的查询会返回多行数据。LIMIT子句用于限制返回的行数。
javaselect * from emp limit 5;
Where语句
-
使用WHERE子句,将不满足条件的行过滤掉
-
WHERE子句紧随FROM子句
比较运算符(Between/In/ Is Null)
下面表中描述了谓词操作符,这些操作符同样可以用于JOIN…ON和HAVING语句中。
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE ,=操作只要匹配不上就返回null |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,其他的和等号(=)操作符的结果一致,如果任一为NULL则结果为NULL |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是一个正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
注意:=是基于比较的,null值不存在两个值相等的情况。
案例
- 查询出薪水等于5000的所有员工
sqlselect * from emp where sal =5000;
- 查询工资在500到1000的员工信息
sqlselect * from emp where sal between 500 and 1000;
- 查询comm为空的所有员工信息
sqlselect * from emp where comm is null;
- 查询工资是1500或5000的员工信息
sqlselect * from emp where sal IN (1500, 5000);
Like和RLike
-
使用LIKE运算选择类似的值
-
选择条件可以包含字符或数字:
- % 代表零个或多个字符(任意个字符)。
- _ 代表一个字符。
-
RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
案例
- 查找以2开头薪水的员工信息
sqlselect * from emp where sal LIKE '2%';
- 查找第二个数值为2的薪水的员工信息
sqlselect * from emp where sal LIKE '_2%';
- 查找薪水中含有2的员工信息
sqlselect * from emp where sal RLIKE '[2]';//使用正则表达式
逻辑运算符(And/Or/Not)
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
案例
- 查询薪水大于1000,部门是30
javaselect * from emp where sal>1000 and deptno=30;
- 查询薪水大于1000,或者部门是30
java select * from emp where sal>1000 or deptno=30;
- 查询除了20部门和30部门以外的员工信息
javaselect * from emp where deptno not IN(30, 20);
分组
Group By语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
案例
- 计算emp表每个部门的平均工资
javaselect t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
- 计算emp每个部门中每个岗位的最高薪水
javaselect t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
Having语句
having与where不同点
- where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据,换句话说,having语句是针对查询结果的。
- where后面不能写分组函数,而having后面可以使用分组函数。
- having只用于group by分组统计语句。
求每个部门的平均薪水大于2000的部门
- 求每个部门的平均工资
javaselect deptno, avg(sal) from emp group by deptno;
- 求每个部门的平均薪水大于2000的部门
javaselect deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
Join语句
等值Join
Hive支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。
案例
根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
javaselect e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
表的别名
好处
-
使用别名可以简化查询。
-
使用表名前缀可以提高执行效率。可以直接定位到表。
案例
合并员工表和部门表
javaselect e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
在mysql中和hive中建立表是有区别的,在mysql中我们尽量建立多张表,减少数据的冗余,但是在hive我们尽量建立宽表,应为hive缺少的是计算资源,多张表在进行join的时候,浪费的是计算资源,所以我们建立表的时候,一般建立宽表存储数据。
内连接
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
javaselect e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
左外链接
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
javaselect e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
右外链接
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
javaselect e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
满外链接
在mysql中不支持满外链接,只能使用union关键字。
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
javaselect e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
多表链接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
javahive (default)>SELECT e.ename, d.deptno, l. loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
-
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l;进行连接操作。
-
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
笛卡尔积
笛卡尔集会在下面条件下产生
-
省略连接条件
-
连接条件无效
-
所有表中的所有行互相连接
案例
java//省略链接条件
select empno, dname from emp, dept;
连接谓词中不支持or
javahive (default)> select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno
= d.deptno or e.ename=d.ename; //错误的
排序
全局排序(Order By)
Order By:全局排序,一个Reducer,对整个数据最后的结果进行全局排序,在hive中可以设置reducer的个数,但是在这里排序的话默认只有1个reducer,尽管设置的reducer个数不是一个。
-
使用 ORDER BY 子句排序
- ASC(ascend): 升序(默认)
- DESC(descend): 降序
-
ORDER BY子句在SELECT语句的结尾
案例
- 查询员工信息按工资升序排列
javaselect * from emp order by sal;
- 查询员工信息按工资降序排列
javaselect * from emp order by sal desc;
按照别名排序
按照员工薪水的2倍排序
javaselect ename, sal*2 twosal from emp order by twosal;
多个列排序
按照部门和工资升序排序(先按照部门排序,然后按照工资排序)
javaselect ename, deptno, sal from emp order by deptno, sal ;
每个MapReduce内部排序(Sort By)
Sort By:每个Reducer内部进行排序,对全局结果集来说不是排序。注意,如果书写的sql语句使用的是order by进行排序,那么不管是否设置了reducer的个数,hive都会按照一个reducer进行处理,最后输出一个全局排序的结果。
- 设置reduce个数
javaset mapreduce.job.reduces=3;
- 查看设置reduce个数
javaset mapreduce.job.reduces
- 根据部门编号降序查看员工信息
javaselect * from emp sort by empno desc;
- 将查询结果导入到文件中(按照部门编号降序排序)
javainsert overwrite local directory '/opt/module/datas/sortby-result'
select * from emp sort by deptno desc;
这里在对数据进行分区的时候,使用的是一个随机算法进行分区。如果使用下面的指定分区,可以对指定分区进行局部排序,使用随机分区,很可能带来数据倾斜问题。
分区排序(Distribute By)
Distribute By:类似MR中partition,进行分区,结合sort by使用。
-
注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
-
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
-
结合sorted by使用,也就是先对数据进行分区操作,然后对分区后的数据进行区内局部排序。
先按照部门编号分区,再按照员工编号降序排序。
javaset mapreduce.job.reduces=3;
insert overwrite local directory '/opt/module/datas/distribute-result'
> select * from emp distribute by deptno sort by empno desc;
最后的结果是先按照部门编号进行分区操作,然后把每一个分区中的数据根据编号进行排序。
Cluster By
当distribute by和sorts by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
以下两种写法等价
javahive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
排序小结
order by:全局排序,设置多个reducer无效,最后输出只有一个文件。
sort by:区内排序,通常结合distribute by使用,但是使用的前提是要把reducer的个数设置为多个。
cluster by:当分区字段和区内排序字段相同的时候,可以使用cluster by代替。
分桶及抽样查询
分桶表数据存储
-
分区针对的是数据的存储路径;分桶针对的是数据文件,也就是说分桶会把数据存储在一个文件夹下面,只是不同的数据以不同的文件形式存在。
-
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑。
-
分桶是将数据集分解成更容易管理的若干部分的另一个技术,数据是以文件形式分开存储。
- 首先设置hive可以进行分区操作,并且设置reducer个数为-1,表示自动设置分桶的个数
javaset hive.enforce.bucketing=true;
set mapreduce.job.reduces=-1;
- 创建一个分桶表
javacreate table stu_buck(id int, name string)
clustered by(id) //表示根据什么字段进行分区操作,这里和分区的区别就是,分区需要重新另外指定一个新的字段作为分区的依据,但是分桶可以使用表中的字段
into 4 buckets//表示分桶的个数
row format delimited fields terminated by '\t';
//可以查看表的结构
desc formatted stu_buck;
- 创建分桶表时,数据通过子查询的方式导入
java//创建普通的查询表
create table stu(id int, name string)
row format delimited fields terminated by '\t';
//导入数据
load data local inpath '/opt/module/data/stud.txt' into table stu_sel;
- 导入数据到分桶表,通过子查询的方式
javainsert into table stu_buck
> select * from stu_sel;
//查询数据
select * from stu_sel;

通过查询结果看到,分桶其实是根据数据的id对分桶的个数进行取模然后分桶的。但是mp中的分区是按照key的哈希值进行分区的。分桶是按照字段的规律进行划分数据。
分桶使用的算法是使用分桶字段的哈希值,然后对桶的个数取模得到的。
分桶抽样查询
- 对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
查询表stu_buck中的数据。
java//表示抽取4/4=1个桶的数据,从第一个桶开始抽取
select * from stu_buck tablesample(bucket 1 out of 4 on id);
//可以看到下面抽取的是第一个桶的数据
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
//表示抽取4/2=2两个桶的数据,从第一个桶开始抽取,第二个抽取的桶是x+y:1+2=3,也就是第三个桶
select * from stu_buck tablesample(bucket 1 out of 2 on id);
//抽取第一个和第三个桶的数据
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
1010 ss10
1002 ss2
1006 ss6
1014 ss14
//表示抽取4/8=0.5 ,也就是在第一个桶中选取一办的数据
select * from stu_buck tablesample(bucket 1 out of 8 on id);
stu_buck.id stu_buck.name
1016 ss16
1008 ss8
//选出全部的数据
select * from stu_buck tablesample(bucket 1 out of 1 on id);
注:tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y) 。
- 其中x表示从哪一个桶开始抽样
- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
- x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
- 注意:x的值必须小于等于y的值
其他常用查询函数
空字段赋值
函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( string1,replace_with)。它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
java//如果comm的值是空,就用empno的值代替
select nvl(comm,empno) from emp;
时间函数
- date_format 时间格式化
javaselect date_format('2020-03-04','yyyy-MM-dd');
//还可以添加时分秒
select date_format('2020-03-04','yyyy-MM-dd HH:mm:ss');
-
时间和天数相加
- date_add()
- date_sub()
javaselect date_add('2020-1-1',5);//加上5天 select date_add('2020-1-1',-5);//5天前的时间 -
两个时间相减
datediff()
java//使用的是前面的时间减后面的时间,可以夸月相减
select datediff('2020-2-3','2020-2-5');
-
时间分隔符替换
regexp_replace()
java//把时间中的/分隔符替换为-
select regexp_replace('2020/03/05','/','-');
CASE WHEN
数据
java悟空 A 男 大海 A 男 宋宋 B 男 凤姐 A 女 婷姐 B 女 婷婷 B 女
要求统计不同部门男女的人数
创建表并且导入数据
javacreate table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/data/info_sex.txt' into table emp_sex;
按照需求进行查询
java//使用case-when
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
//使用if
select dept_id,sum(if(sex='男',1,0)) as male_count,sum(if(sex='女',1,0)) as female_count from emp_sex group by dept_id;
//if(bool表达式,真的结果,假的返回结果)
行转列
实际上是合并多个列的操作
相关函数说明
-
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
-
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
-
COLLECT_SET(col)(聚合函数):函数只接受基本数据类型,它的主要作用是将某字段(也就是列去重)的值进行去重汇总,产生array类型字段。类似还有collect_list( collect_set( collection函数
案例说明
sql-- concat()函数
select concat(dname,loc) from dept;
-- 支持不同的分隔符分隔
select concat(deptno,'-',dname,'/',loc) from dept;
-- 分隔符都一样
select concat_ws('-','hello','word','hi');
-- 也可以合并多个列,但是列的类型需要是字符串类型
-- 对deptno做去重操作,最后的结果放在数组中
select collect_set(deptno) from dept;
-- [10,20,30,40]
-- 不做去重操作,直接把结果放在list列表数组中,列的类型也可以是字符串类型
select collect_list(deptno) from dept;
[10,20,30,40]
-- collect_set函数和concat_ws()函数连用,把数组中的元素全部链接起来
select concat_ws('-',collect_set(dname)) from dept;
ACCOUNTING-RESEARCH-SALES-OPERATIONS
数据准备
sqlname constellation blood_type 孙悟空 白羊座 A 大海 射手座 A 宋宋 白羊座 B 猪八戒 白羊座 A 凤姐 射手座 A
需求
sql--把星座和血型一样的人归类到一起。结果如下:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
创建表
sqlcreate table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
-- 加载数据
load data local inpath '/opt/module/data_/constellation.txt'into table person_info;
查询
sql-- 第一步,先把数据变为下面的样子
射手座,A 大海
射手座,A 凤姐
白羊座,A 孙悟空
白羊座,A 猪八戒
白羊座,B 宋宋
select concat(constellation,',',blood_type) as constellation_blood_type,name from person_info;
-- 产生结果为
onstellation_blood_type name
白羊座,A 孙悟空
射手座,A 大海
白羊座,B 宋宋
白羊座,A 猪八戒
射手座,A 凤姐
-- 第二部
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
列转行
就是把某一行中多个值转换为多个行的操作
-
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
-
LATERAL VIEW
- 用法:LATERAL VIEW udtf(expression) tableAlias(表别名) AS columnAlias(列别名)
- 解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
- 用法:LATERAL VIEW udtf(expression) tableAlias(表别名) AS columnAlias(列别名)
数据准备
sqlmovie category
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
需求
sql--将电影分类中的数组数据展开。结果如下:
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
创建表操作
sqlcreate table movie_info(
movie string,
category array<string>
)
row format delimited fields terminated by "\t"
collection items terminated by ",";
load data local inpath '/opt/module/data_/movie.txt' into table movie_info;
查询
sql-- 炸裂函数使用,会把一行中的多个值全部转换为行
hive (default)> select explode(category) from movie_info;
OK
col
悬疑
动作
科幻
剧情
悬疑
警匪
动作
心理
剧情
战争
动作
灾难
select
movie,
category_name
from
movie_info lateral view explode(category) table_tmp as category_name;
窗口函数
窗口函数会针对每一条记录进行开窗口,窗口的大小是用over()函数里面的参数决定的
相关函数说明
-
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
- CURRENT ROW:当前行
- n PRECEDING:往前n行数据
- n FOLLOWING:往后n行数据
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
- 上面的都是over()函数里面的参数,都是用来限定over函数中数据及的大小
下面的参数在over()函数外使用,必须和over()函数搭配使用
-
LAG(col,n):往前第n行数据
-
LEAD(col,n):往后第n行数据
-
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
数据准备
javaname,orderdate,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
需求
-
查询在2017年4月份购买过的顾客及总人数
-
查询顾客的购买明细及月购买总额
-
上述的场景,要将cost按照日期进行累加
-
查询顾客上次的购买时间
-
查询前20%时间的订单信息
创建表
sqlcreate table business(
name string,
orderdate string,
cost int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- 导入数据
load data local inpath '/opt/module/data_/business.txt' into table business;
按需求查询
- 查询在2017年4月份购买过的顾客及总人数
sqlselect name,count(*) over () -- 使用over函数进行开窗操作
from business
where substring(orderdate,1,7) = '2017-04'
group by name;
-- over()函数没有参数说明是对整个数据进行开窗,对每一条数据记录开一个窗口
-- 如果没有over()窗口函数,那么返回的是在2017-04买东西的人
select name,count(*)
from business
where substring(orderdate,1,7) = '2017-04'
group by name;--这里相当于做去重操作,去重有两种方式,distinct()和group by去重
-- 返回结果
name _c1
jack 1
mart 4
-- 添加上over函数,也就是说针对上面返回的每一个结果,over()都开一个全局的窗口进行累加计算
-- 先对jack开窗,然后对marka开全局窗口,针对结果开窗口,有几条数据,就开几个窗口
name count_window_0
mart 2
jack 2
-- 仅仅查询名字,查看over()函数和group by()函数的区别
select name,count(*) over()
from business
where substring(orderdate,1,7) = '2017-04';
-- 返回结果是,对每一条记录开相同大小的窗口,开窗是对每一条数据记录进行开窗,在计算count()函数时候,每一个记录都对应有自己的窗口,窗口大小要看over()函数
name count_window_0
mart 5
mart 5
mart 5
mart 5
jack 5
-- 但是如果使用的是group by 返回的是mark 4,jack 1
- 查询顾客的购买明细及月购买总额
javaselect * ,sum(cost) over() from business;'
business.name business.orderdate business.cost sum_window_0
NULL NULL 661
mart 2017-04-13 94 661
neil 2017-06-12 80 661
mart 2017-04-11 75 661
neil 2017-05-10 12 661
mart 2017-04-09 68 661
mart 2017-04-08 62 661
jack 2017-01-08 55 661
tony 2017-01-07 50 661
jack 2017-04-06 42 661
jack 2017-01-05 46 661
tony 2017-01-04 29 661
jack 2017-02-03 23 661
tony 2017-01-02 15 661
jack 2017-01-01 10 661
- 上述的场景,要将cost按照日期进行累加
sqlselect orderdate,cost,sum(cost) over (order by orderdate) from business
-- 结果
orderdate cost sum_window_0
NULL NULL NULL
2017-01-01 10 10
2017-01-02 15 25
2017-01-04 29 54
2017-01-05 46 100
2017-01-07 50 150
2017-01-08 55 205
2017-02-03 23 228
2017-04-06 42 270
2017-04-08 62 332
2017-04-09 68 400
2017-04-11 75 475
2017-04-13 94 569
2017-05-10 12 581
2017-06-12 80 661
-- 解释:在这,我们对窗口的限定是order by 函数,每次查询一条记录的时候,开的窗口是比当前记录小的记录总和窗口的大小,所以窗口是一个动态的变化
-- 窗口中写得内容是限定当前记录使用的窗口的大小
-- 计算每一个人的消费明细
select orderdate,cost,sum(cost) over (distribute by name) from business
-- 语法上面不支持group by 做法,使用distribute by 是做分区操作,先按照名字分区,然后累加
orderdate cost sum_window_0
NULL NULL NULL
2017-01-08 55 176
2017-04-06 42 176
2017-01-05 46 176
2017-02-03 23 176
2017-01-01 10 176
2017-04-08 62 299
2017-04-13 94 299
2017-04-11 75 299
2017-04-09 68 299
2017-06-12 80 92
2017-05-10 12 92
2017-01-07 50 94
2017-01-04 29 94
2017-01-02 15 94
--累加每一个人的消费明细
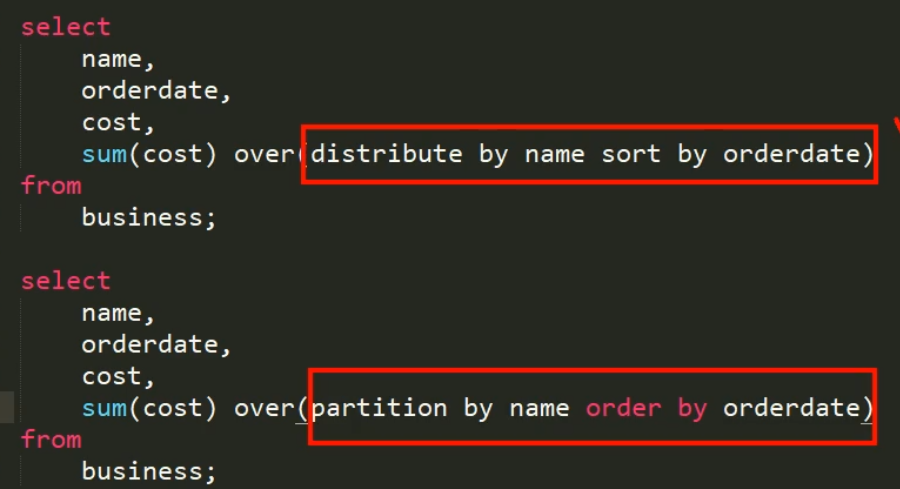
select orderdate,cost,sum(cost) over (distribute by name sort by orderdate) from business
-- sort by 是针对每一个分区再一次做排序操作,over里面的内容都是对窗口的限定操作,先按照名字进行分区,然后在排序
orderdate cost sum_window_0
NULL NULL NULL
2017-01-01 10 10
2017-01-05 46 56
2017-01-08 55 111
2017-02-03 23 134
2017-04-06 42 176
2017-04-08 62 62
2017-04-09 68 130
2017-04-11 75 205
2017-04-13 94 299
2017-05-10 12 12
2017-06-12 80 92
2017-01-02 15 15
2017-01-04 29 44
2017-01-07 50 94
参数使用
sqlselect name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
-
查看顾客上次的购买时间
lag()函数
sqlselect name,orderdate,cost,lag(orderdate,1,'2020-1') over(distribute by name sort by orderdate) from business;
-- 为防止结果又null值。可以给lag()函数添加第三个参数默认值
name orderdate cost lag_window_0
NULL NULL NULL
jack 2017-01-01 10 NULL
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 NULL
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
mart 2017-04-13 94 2017-04-11
neil 2017-05-10 12 NULL
neil 2017-06-12 80 2017-05-10
tony 2017-01-02 15 NULL
tony 2017-01-04 29 2017-01-02
tony 2017-01-07 50 2017-01-04
---查看下一次购买时间
select name,orderdate,cost,lead(orderdate,1,'2020-1') over(distribute by name sort by orderdate) from business;
name orderdate cost lead_window_0
NULL NULL 2020-1
jack 2017-01-01 10 2017-01-05
jack 2017-01-05 46 2017-01-08
jack 2017-01-08 55 2017-02-03
jack 2017-02-03 23 2017-04-06
jack 2017-04-06 42 2020-1
mart 2017-04-08 62 2017-04-09
mart 2017-04-09 68 2017-04-11
mart 2017-04-11 75 2017-04-13
mart 2017-04-13 94 2020-1
neil 2017-05-10 12 2017-06-12
neil 2017-06-12 80 2020-1
tony 2017-01-02 15 2017-01-04
tony 2017-01-04 29 2017-01-07
tony 2017-01-07 50 2020-1
-- 查询当前3行的消费明细
select name,orderdate,cost,sum(cost) over(rows between 2 preceding and current row) from business;
name orderdate cost sum_window_0
NULL NULL NULL
mart 2017-04-13 94 94
neil 2017-06-12 80 174
mart 2017-04-11 75 249
neil 2017-05-10 12 167
mart 2017-04-09 68 155
mart 2017-04-08 62 142
jack 2017-01-08 55 185
tony 2017-01-07 50 167
jack 2017-04-06 42 147
jack 2017-01-05 46 138
tony 2017-01-04 29 117
jack 2017-02-03 23 98
tony 2017-01-02 15 67
jack 2017-01-01 10 48
--计算当前行和后两行的累加和
select name,orderdate,cost,sum(cost) over(rows between current row and 2 following ) from business;
name orderdate cost sum_window_0
NULL NULL 174
mart 2017-04-13 94 249
neil 2017-06-12 80 167
mart 2017-04-11 75 155
neil 2017-05-10 12 142
mart 2017-04-09 68 185
mart 2017-04-08 62 167
jack 2017-01-08 55 147
tony 2017-01-07 50 138
jack 2017-04-06 42 117
jack 2017-01-05 46 98
tony 2017-01-04 29 67
jack 2017-02-03 23 48
tony 2017-01-02 15 25
jack 2017-01-01 10 10
--分组函数
select name,orderdate,cost,ntile(5) over() from business;
-- ntile()里面的参数表示平均分成几个组
name orderdate cost ntile_window_0
NULL NULL 1
mart 2017-04-13 94 1
neil 2017-06-12 80 1
mart 2017-04-11 75 2
neil 2017-05-10 12 2
mart 2017-04-09 68 2
mart 2017-04-08 62 3
jack 2017-01-08 55 3
tony 2017-01-07 50 3
jack 2017-04-06 42 4
jack 2017-01-05 46 4
tony 2017-01-04 29 4
jack 2017-02-03 23 5
tony 2017-01-02 15 5
jack 2017-01-01 10 5
over()函数中的分区+排序
- (1)查询前20%时间的订单信息
sqlselect * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
Rank
rank()是窗口函数,必须和over()函数搭配使用
函数说明
-
RANK() 排序相同时会重复,总数不会变
-
DENSE_RANK() 排序相同时会重复,总数会减少
-
ROW_NUMBER() 会根据顺序计算
数据准备
sqlname subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
需求
计算每门学科成绩排名。
创建表
sqlcreate table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/data_/score.txt' into table score;
按照需求查询
sqlselect name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
name subject score rp drp rmp
NULL NULL 1 1 1
孙悟空 数学 95 1 1 1
宋宋 数学 86 2 2 2
婷婷 数学 85 3 3 3
大海 数学 56 4 4 4
宋宋 英语 84 1 1 1
大海 英语 84 1 1 2
婷婷 英语 78 3 2 3
孙悟空 英语 68 4 3 4
大海 语文 94 1 1 1
孙悟空 语文 87 2 2 2
婷婷 语文 65 3 3 3
宋宋 语文 64 4 4 4
函数
所有的聚合函数,用户自定义函数和内置函数,统称为用户自定义聚合函数(UDAF),聚合函数接受从零行到多行或零个到多个列,然后返回单一的值,
系统内置函数
- 查看系统的函数
sqlshow functions;
- 显示自带的函数用法
sql desc function upper;
- 详细显示函数的用法
sqldesc function extended upper;
自定义函数
-
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
-
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
-
- 聚集函数,多进一出, 类似于:count/max/min
- UDTF(User-Defined Table-Generating Functions)
- 一进多出, 如lateral view explore(),接受零个或者多个输入,然后产生多列或者多行输出
注意:这里的一进多出,或者一进一出是针对数据的行来说的,多行输进去,最后输出一个结果。
自定义函数步骤
-
继承org.apache.hadoop.hive.ql.UDF
-
需要实现evaluate函数;evaluate函数支持重载;支持重载的目的就是为了实现可变参数,当然也可以使用可变参数的函数,但是参数类型不一致的话无法返回,所以最好使用重载的方式
-
在hive的命令行窗口创建函数
- 添加jar:add jar linux_jar_path(函数最好放在hive的lib目录下,因为启动hive后hive会加载lib目录下的jar包)
- 创建function,
javacreate [temporary] function [dbname.]function_name AS class_name(全类名); //temporary表示创建临时函数,重新启动hive的话,函数会失效 -
在hive的命令行窗口删除函数
sqlDrop [temporary] function [if exists] [dbname.]function_name;
注意事项
UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
自定义udf函数
- 创建一个maven工程,然后倒入依赖
sql<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
- 创建一个类,继承UDF
javapublic class Lower extends UDF {
//evaluate是系统的寒暑表名
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
//重载函数,实现多个参数
public String evaluate (final String s,String s1) {
if (s == null) {
return null;
}
return s.toLowerCase()+s1;
}
}
- 打成jar包上传到服务器/opt/module/jars/udf.jar,就是对java程序进行打包操作
- 将jar包添加到hive的classpath,这里也可以放在hive的lib目录下面
sqlhive (default)> add jar /opt/module/datas/udf.jar;
- 创建临时函数与开发好的java class关联
javahive (default)> create temporary function mylower as "com.rzf.hive.Lower";
- 即可在hql中使用自定义的函数strip
sqlhive (default)> select ename, mylower(ename) lowername from emp;
自定义UDF函数小结
- 继承
org.apache.hadoop.hive.ql.exec.UDF - 需要实现
evaluate函数;evaluate函数支持重载,不可以修改函数名; - 在
hive的命令行窗口创建函数 - 如果自定义函数要输入多个参数怎么办,就重载
EVALUTE()方法,每个方法中的参数不同即可,也可以用可变形参的方法,但是局限性在于可变形参的类型必须一样。
自定义UDTF函数(一进多出)
- 创建类继承GenericUDTF
javapublic class MyUdtf extends GenericUDTF {
private List<String> list=new ArrayList<String>();
// 进行初始化操作,定义输出数据类型
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//定义输出数据的类型
List<String> fieldNames=new ArrayList<String>();//列明
// 添加输出数据的列明
fieldNames.add("fields");
// 定义输出数据的类型
List<ObjectInspector> fieldOIs=new ArrayList<ObjectInspector>();//返回值
// 定义输出类型,javaStringObjectInspector是hive里面的类型
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
public void process(Object[] objects) throws HiveException {
// 1 获取数据
String data = objects[0].toString();
// 2 获取分隔符
String splitKey = objects[1].toString();
// 3 切分数据
String[] fields = data.split(splitKey);
// 4 遍历循环写出数据
for (String word:fields) {
list.clear();
// 5 将数据添加到集合中
list.add(word);
// 6 写出数据
forward(list);
}
// 因为初始化中输出类型是一个集合,所以我们定义全局的集合,写出数据
}
public void close() throws HiveException {
}
}
- 添加到classpath路径中
sqladd jar /opt/module/hive/lib/MyUDTF.jar
- 创建函数
sqlcreate function myudtf as 'rzf.qq.com.MyUdtf'
- 使用函数
sqlhive (default)> select myudtf('hello,word,rzf',',');
OK
fields //列的名字是我们在函数中写得名字,在查询的时候可以进行修改
hello
word
rzf
自定义UDTF函数总结
- 自定义类继承
genericUDTF类。 - 实现其三个方法:
initialize,process,close等三个方法。 initialize函数里面声明输出参数的名称和类型,process里面写具体处理的业务逻辑,close关闭流操作。
压缩和存储
Hadoop压缩配置
MR支持的压缩编码
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .deflate | 否 |
| Gzip | gzip | DEFAULT | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 是 |
| Snappy | 无 | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
案例
- 开启hive中间传输数据压缩功能
java//hive.exec.compress.intermediate=false 默认是没有开启的
set hive.exec.compress.intermediate=true;
- 开启mapreduce中map输出压缩功能
javamapreduce.map.output.compress=false // 默认是没有开启的
mapreduce.map.output.compress=true
- 设置mapreduce中map输出数据的压缩方式
java//默认情况下:使用的是默认的压缩方式
set mapreduce.map.output.compress.codec;
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
//下面设置为snappy压缩
set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
案例
- 开启hive最终输出数据压缩功能
javahive.exec.compress.output=false // 默认的值也是false
hive.exec.compress.output=true //设置为true
- 开启mapreduce最终输出数据压缩
javahive (default)> set mapreduce.output.fileoutputformat.compress;
mapreduce.output.fileoutputformat.compress=false //默认是false
set mapreduce.output.fileoutputformat.compress=true;
- 设置mapreduce最终数据输出压缩方式
javahive (default)> set mapreduce.output.fileoutputformat.compress.codec;
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec//默认使用的是默认的压缩方式
set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
- 设置mapreduce最终数据输出压缩为块压缩
javahive (default)> set mapreduce.output.fileoutputformat.compress.type;
mapreduce.output.fileoutputformat.compress.type=RECORD//默认的压缩方式是行压缩
//设置为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
企业级优化
Fetch抓取
- Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
- 在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
sql<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
案例
- 把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
sqlhive (default)> set hive.fetch.task.conversion=none;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
- 把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
sqlhive (default)> set hive.fetch.task.conversion=more;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
本地模式
- 大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
- 用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
javaset hive.exec.mode.local.auto=true; //开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
案例实操
- 开启本地模式,并执行查询语句
sqlset hive.exec.mode.local.auto=true;
//执行查询
select count(*) from emp;
Automatically selecting local only mode for query
Query ID = rzf_20210220112352_1b180659-58b1-4693-89ac-4576b7e4aedc
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2021-02-20 11:23:55,966 Stage-1 map = 100%, reduce = 0%
2021-02-20 11:23:58,011 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1712281398_0001 //这里看出是本地运行
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 2604 HDFS Write: 3 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
如果现在把emp表下面添加的文件数目大于4个,即使设置的是本地模式,那也不会走本地模式,会走mr程序
现在重新执行查询操作
javahive (default)> select count(*) from emp;
Query ID = rzf_20210220113249_21c734e5-ebf8-4753-a232-f7a9df8bdab1
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Cannot run job locally: Number of Input Files (= 5) is larger than//文件大于5,不可以使用本地模式 hive.exec.mode.local.auto.input.files.max(= 4)
Starting Job = job_1613785538686_0001, Tracking URL = http://hadoop101:8088/proxy/application_1613785538686_0001/
Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1613785538686_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-02-20 11:33:05,483 Stage-1 map = 0%, reduce = 0%
2021-02-20 11:33:15,159 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.98 sec
2021-02-20 11:33:25,589 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.6 sec
MapReduce Total cumulative CPU time: 4 seconds 600 msec
Ended Job = job_1613785538686_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.6 sec HDFS Read: 8734 HDFS Write: 3 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 600 msec
OK
_c0
30
表的优化
小表驱动大表
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
实际测试发现:新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。
案例实操
测试大表JOIN小表和小表JOIN大表的效率
建大表、小表和JOIN后表的语句
sql// 创建大表
create table bigtable(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建小表
create table smalltable(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建join后表的语句
create table jointable(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
分别向大表和小表中导入数据
sqlload data local inpath '/opt/module/data_/bigtable' into table bigtable;
load data local inpath '/opt/module/data_/smalltable' into table smalltable;
关闭mapjoin功能(默认是打开的)
sqlset hive.auto.convert.join = false;
执行小表JOIN大表语句
sqlinsert overwrite table jointable
select b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
left join bigtable b
on b.id = s.id;
Time taken: 39.457 seconds
如果重新打开maojoin功能执行join操作
sqlset hive.auto.convert.join = true
insert overwrite table jointable
select b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
left join bigtable b
on b.id = s.id;
Time taken: 37.189 seconds
执行大表join小表
sqlinsert overwrite table jointable
select b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
left join smalltable s
on s.id = b.id;
Time taken: 34.196 seconds
大表join大表
空key的过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。例如key对应的字段为空,操作如下:
案例实操
- 配置历史服务器
sql-- 配置mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
- 启动历史服务器
sqlsbin/mr-jobhistory-daemon.sh start historyserver
- 创建原始数据表、空id表、合并后数据表
sql// 创建原始表
create table ori(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建空id表
create table nullidtable(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
// 创建join后表的语句
create table jointable1(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';
- 加载数据
sqlload data local inpath '/opt/module/data_/ori' into table ori;
load data local inpath '/opt/module/data_/nullid' into table nullidtable;
- 测试不过滤空id
sqlinsert overwrite table jointable
select n.* from nullidtable n left join ori o on n.id = o.id;
Time taken: 45.234 seconds
//一共5个map阶段,2个reducer阶段
- 测试过滤空id
sqlinsert overwrite table jointable
select n.* from (select * from nullidtable where id is not null ) n left join ori o on n.id = o.id;
Time taken: 32.756 seconds
空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。例如:
案例实操
不随机分布空null值:
- 设置5个reduce个数
sqlset mapreduce.job.reduces = 5;
- JOIN两张表
sqlinsert overwrite table jointable
select n.* from nullidtable n left join ori b on n.id = b.id;
//结果:如图6-13所示,可以看出来,出现了数据倾斜,某些reducer的资源消耗远大于其他reducer。
随机分布空null值
- 设置5个reduce个数
sqlset mapreduce.job.reduces = 5;
- JOIN两张表
sqlinsert overwrite table jointable
select n.* from nullidtable n full join ori o on
case when n.id is null then concat('hive', rand()) else n.id end = o.id;
//结果:如图6-14所示,可以看出来,消除了数据倾斜,负载均衡reducer的资源消耗

MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
- 开启MapJoin参数设置
java//设置自动选择Mapjoin
set hive.auto.convert.join = true; 默认为true
//大表小表的阈值设置(默认25M一下认为是小表):
set hive.mapjoin.smalltable.filesize=25000000;
- mapjoin工作机制
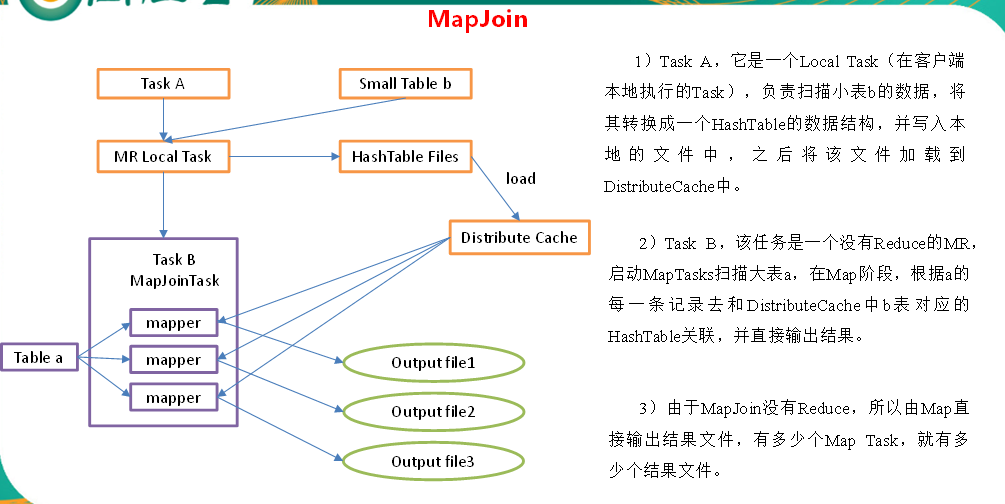
案例实操
- 开启Mapjoin功能
sqlset hive.auto.convert.join = true; 默认为true
- 执行小表JOIN大表语句
sqlinsert overwrite table jointable
select b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from smalltable s
join bigtable b
on s.id = b.id;
- 执行大表JOIN小表语句
sqlinsert overwrite table jointable
select b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable b
join smalltable s
on s.id = b.id;
由于已经对hive做了优化,所以大表join小表还是小表join大表都可以
Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
- 开启Map端聚合参数设置
sql--是否在Map端进行聚合,默认为True
hive.map.aggr = true
-- 在Map端进行聚合操作的条目数目
hive.groupby.mapaggr.checkinterval = 100000
--有数据倾斜的时候进行负载均衡(默认是false)
hive.groupby.skewindata = true
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
案例
- 创建一张大表
sqlhive (default)> create table bigtable(id bigint, time bigint, uid string, keyword
string, url_rank int, click_num int, click_url string) row format delimited
fields terminated by '\t';
- 加载数据
sqlload data local inpath '/opt/module/datas/bigtable' into table
bigtable;
- 设置5个reduce个数
sqlset mapreduce.job.reduces = 5;
- 执行去重id查询
sqlselect count(distinct id) from bigtable;
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.12 sec HDFS Read: 120741990 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 120 msec
OK
c0
100001
Time taken: 23.607 seconds, Fetched: 1 row(s)
- 采用GROUP by去重id
sqlhive (default)> select count(id) from (select id from bigtable group by id) a;
Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 17.53 sec HDFS Read: 120752703 HDFS Write: 580 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.29 sec HDFS Read: 9409 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 21 seconds 820 msec
OK
_c0
100001
Time taken: 50.795 seconds, Fetched: 1 row(s)
-- 虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
笛卡尔乘积
尽量避免笛卡尔积,join的时候不加on条件,或者无效的on条件,Hive只能使用1个reducer来完成笛卡尔积。
行列过滤
-
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
-
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,比如:
- 测试先关联两张表,再用where条件过滤
sqlselect o.id from bigtable b
join ori o on o.id = b.id
where o.id <= 10;
--这条sql语句会先进行两个表的关联,然后在执行where语句中的条件过滤
- 通过子查询后,再关联表
sqlselect b.id from bigtable b
join (select id from ori where id <= 10 ) o on b.id = o.id;
--产生子表,先从ori表中执行条件查询,执行完后相当于一个小表,然后在使用小表关联大表
动态分区调整
关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
- 开启动态分区参数设置
java//开启动态分区功能(默认true,开启)
set hive.exec.dynamic.partition=true;
- 设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
sql set hive.exec.dynamic.partition.mode=nonstrict;
- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
javahive.exec.max.dynamic.partitions=1000
- 在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
javahive.exec.max.dynamic.partitions.pernode=100 //每一个节点的分区数
- )整个MR Job中,最大可以创建多少个HDFS文件。
javahive.exec.max.created.files=100000
- 当有空分区生成时,是否抛出异常。一般不需要设置。
javahive.error.on.empty.partition=false
案例
- 创建分区表
sqlcreate table dept_par(dname string,loc int) partitioned by(deptno int)row format delimited fields terminated by '\t';
- 插入数据
sqlinsert into table dept_par partition(deptno) select dname,loc,deptno from dept;
--可以看到,一共分四个分区
Loading partition {deptno=30}
Loading partition {deptno=10}
Loading partition {deptno=40}
Loading partition {deptno=20}
hive (default)> select * from dept_par;
OK
dept_par.dname dept_par.loc dept_par.deptno
ACCOUNTING 1700 10
RESEARCH 1800 20
SALES 1900 30
OPERATIONS 1700 40
--可以发现是根据deptno列进行分区操作的
- 删除原有的分区
sqlalter table dept_par drop partition(deptno=10),partition(deptno=20),partition(deptno=30),partition(deptno=40);
- 重新查询并且插入数据
sqlinsert into table dept_par partition(deptno) select deptno,dname,loc from dept;
//分区结果
Loading partition {deptno=1700}
Loading partition {deptno=1900}
Loading partition {deptno=1800}
dept_par.dname dept_par.loc dept_par.deptno
10 NULL 1700
40 NULL 1700
20 NULL 1800
30 NULL 1900
//可以发现是根据loc列进行分区操作的
-- 所以动态分区是根据位置进行划分分区的,一般是根据查询的最后一个字段进行分区的
-- 分区的名字可以随便写
分桶,分区
详见前面介绍
数据倾斜
Hive实战之谷粒影音
需求描述
统计硅谷影音视频网站的常规指标,各种TopN指标:
-
统计视频观看数Top10,有自带视频观看数量
-
统计视频类别热度Top10,以类别视频的合数定义热度
-
统计视频观看数Top20所属类别
-
统计视频观看数Top50所关联视频的所属类别Rank,用到关联视频字段
-
统计每个类别中的视频热度Top10
-
统计每个类别中视频流量Top10
-
统计上传视频最多的用户Top10以及他们上传的视频
-
统计每个类别视频观看数Top10
项目
数据结构
视频表
| 字段 | 备注 | 详细描述 |
|---|---|---|
| video id | 视频唯一id | 11位字符串 |
| uploader | 视频上传者 | 上传视频的用户名String |
| age | 视频年龄 | 视频在平台上的整数天 |
| category | 视频类别 | 上传视频指定的视频分类(数组类型) |
| length | 视频长度 | 整形数字标识的视频长度 |
| views | 观看次数 | 视频被浏览的次数 |
| rate | 视频评分 | 满分5分 |
| ratings | 流量 | 视频的流量,整型数字 |
| conments | 评论数 | 一个视频的整数评论数 |
| related ids | 相关视频id | 相关视频的id,最多20个(数组类型) |
用户表
| 字段 | 备注 | 字段类型 |
|---|---|---|
| uploader | 上传者用户名 | string |
| videos | 上传视频数 | int |
| friends | 朋友数量 | int |
ETL原始数据
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
ETL之ETLUtil
javapublic class ETLUtil {
public static String oriString2ETLString(String ori){
StringBuilder etlString = new StringBuilder();
String[] splits = ori.split("\t");
if(splits.length < 9) return null;
splits[3] = splits[3].replace(" ", "");
for(int i = 0; i < splits.length; i++){
if(i < 9){
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "\t");
}
}else{
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "&");
}
}
}
return etlString.toString();
}
}
ETL之Mapper
javapublic class VideoETLMapper extends Mapper<Object, Text, NullWritable, Text>{
Text text = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String etlString = ETLUtil.oriString2ETLString(value.toString());
if(StringUtils.isBlank(etlString)) return;
text.set(etlString);
context.write(NullWritable.get(), text);
}
}
ETL之Runner
javapublic class VideoETLRunner implements Tool {
private Configuration conf = null;
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return this.conf;
}
@Override
public int run(String[] args) throws Exception {
conf = this.getConf();
conf.set("inpath", args[0]);
conf.set("outpath", args[1]);
Job job = Job.getInstance(conf);
job.setJarByClass(VideoETLRunner.class);
job.setMapperClass(VideoETLMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
this.initJobInputPath(job);
this.initJobOutputPath(job);
return job.waitForCompletion(true) ? 0 : 1;
}
private void initJobOutputPath(Job job) throws IOException {
Configuration conf = job.getConfiguration();
String outPathString = conf.get("outpath");
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path(outPathString);
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
}
private void initJobInputPath(Job job) throws IOException {
Configuration conf = job.getConfiguration();
String inPathString = conf.get("inpath");
FileSystem fs = FileSystem.get(conf);
Path inPath = new Path(inPathString);
if(fs.exists(inPath)){
FileInputFormat.addInputPath(job, inPath);
}else{
throw new RuntimeException("HDFS中该文件目录不存在:" + inPathString);
}
}
public static void main(String[] args) {
try {
int resultCode = ToolRunner.run(new VideoETLRunner(), args);
if(resultCode == 0){
System.out.println("Success!");
}else{
System.out.println("Fail!");
}
System.exit(resultCode);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
}
上传数据
将数据上传到hdfs上面
执行ETL数据清洗
sql -- 使用yarn jar或者hadoop jar都可以
bin/yarn jar /opt/module/jar/guliVideo-1.0-SNAPSHOT.jar(jar包路径) com.qq.rzf.ETLDriver(全类名) /video/2008/0222(输入文件路径) /gulioutput(输出文件路径)
[rzf@hadoop100 hadoop-2.7.2]$ bin/yarn jar /opt/module/jar/guliVideo-1.0-SNAPSHOT.jar com.qq.rzf.ETLDriver /video/2008/0222 /gulioutput
21/02/21 14:56:01 INFO client.RMProxy: Connecting to ResourceManager at hadoop101/192.168.37.129:8032
21/02/21 14:56:03 INFO input.FileInputFormat: Total input paths to process : 5
21/02/21 14:56:03 INFO mapreduce.JobSubmitter: number of splits:5
21/02/21 14:56:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1613890035811_0001
21/02/21 14:56:04 INFO impl.YarnClientImpl: Submitted application application_1613890035811_0001
21/02/21 14:56:04 INFO mapreduce.Job: The url to track the job: http://hadoop101:8088/proxy/application_1613890035811_0001/
21/02/21 14:56:04 INFO mapreduce.Job: Running job: job_1613890035811_0001
21/02/21 14:56:16 INFO mapreduce.Job: Job job_1613890035811_0001 running in uber mode : false
21/02/21 14:56:16 INFO mapreduce.Job: map 0% reduce 0%
21/02/21 14:56:25 INFO mapreduce.Job: map 40% reduce 0%
21/02/21 14:56:26 INFO mapreduce.Job: map 60% reduce 0%
21/02/21 14:56:27 INFO mapreduce.Job: map 80% reduce 0%
21/02/21 14:56:29 INFO mapreduce.Job: map 100% reduce 0%
21/02/21 14:56:36 INFO mapreduce.Job: map 100% reduce 100%
21/02/21 14:56:36 INFO mapreduce.Job: Job job_1613890035811_0001 completed successfully
21/02/21 14:56:37 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=364966149
FILE: Number of bytes written=582258791
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=213621057
HDFS: Number of bytes written=212238254
HDFS: Number of read operations=18
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=5
Launched reduce tasks=1
Data-local map tasks=5
Total time spent by all maps in occupied slots (ms)=42143
Total time spent by all reduces in occupied slots (ms)=8411
Total time spent by all map tasks (ms)=42143
Total time spent by all reduce tasks (ms)=8411
Total vcore-milliseconds taken by all map tasks=42143
Total vcore-milliseconds taken by all reduce tasks=8411
Total megabyte-milliseconds taken by all map tasks=43154432
Total megabyte-milliseconds taken by all reduce tasks=8612864
Map-Reduce Framework
Map input records=749361
Map output records=743569
Map output bytes=213669185
Map output materialized bytes=216587589
Input split bytes=540
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=216587589
Reduce input records=743569
Reduce output records=743569
Spilled Records=1997100
Shuffled Maps =5
Failed Shuffles=0
Merged Map outputs=5
GC time elapsed (ms)=1757
CPU time spent (ms)=24160
Physical memory (bytes) snapshot=1529044992
Virtual memory (bytes) snapshot=12689920000
Total committed heap usage (bytes)=1092091904
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=213620517
File Output Format Counters
Bytes Written=212238254
0
准备工作
创建表
首先创建原始表,从原始表中导入数据
-
创建表:gulivideo_ori,gulivideo_user_ori,原始表,以text文件形式存储
-
创建表:gulivideo_orc,gulivideo_user_orc,以orc文件格式进行存储
sql-- gulivideo_ori:
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "\t"-- 字段(属性)之间使用\t分隔
collection items terminated by "&" --集合元素之间使用&分隔
stored as textfile;--以文本格式存储
-- 创建用户表
--gulivideo_user_ori:
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
导入数据
sqlload data inpath '/gulioutput/part-r-00000' into table gulivideo_ori;
load data inpath '/user/2008/0903/user.txt' into table gulivideo_user_ori;
创建以orc的格式进行存储的表
- 直接以load命令导入数据的话,不会以orc格式进行存储,所以创建以orc格式存储的表,然后使用查询的方式导入数据
sql--gulivideo_orc:
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as orc;-- 仅仅是这里存储方式的区别
--gulivideo_user_orc:
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc;
向ORC表插入数据
sql--gulivideo_orc:
insert into table gulivideo_orc select * from gulivideo_ori;
--gulivideo_user_orc:
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
业务分析
统计视频观看数Top10
可以根据视频的观看数量,也就是views字段进行排序
思路:使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
最终代码:
sqlselect videoId,views from gulivideo_orc order by views desc limit 10;
统计视频类别热度Top10
我们一每种类别视频的个数来作为视频热度的判断依据
思路:
-
即统计每个类别有多少个视频,显示出包含视频最多的前10个类别。
-
我们需要按照类别group by聚合(先按照视频的类别进行分组),然后count组内的videoId个数即可。
-
因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by类别,需要先将类别进行列转行(展开),然后再进行count即可。也就是首先需要做炸裂操作。
-
最后按照热度排序,显示前10条。
- 第一步,炸裂分类列
sql--某一类视频的个数,作为视频的热度
-- 1 使用炸裂函数将视频类别列炸裂开,需要炸裂category这一列数据,是以数组形式存储的
select videoId,category_name from gulivideo_orc lateral view explode(category) tmp_category as category_name limit 10;t1
videoid category_name
o4x-VW_rCSE Entertainment
P1OXAQHv09E Comedy
N0TR0Irx4Y0 Comedy
seGhTWE98DU Music
bNF_P281Uu4 Travel -- 可以看到一个视频。可能属于多个类别
bNF_P281Uu4 Places
CQO3K8BcyGM Comedy
3gg5LOd_Zus Entertainment
--一个视频属于两种类别
sdUUx5FdySs Film
sdUUx5FdySs Animation
- 第二步,分组统计没一类视频的个数
sql-- 第二部:分组计数
-- 2 按照category_name进行分组计数,然后排序取出前十名
select category_name,count(*) as category_count from t1 group by category_name order by category_count desc limit 10;
-- 最终的sql语句
select category_name,count(*) as category_count from (select videoId,category_name from gulivideo_orc lateral view explode(category) tmp_category as category_name ) t1 group by category_name order by category_count desc limit 10;
category_name category_count
Music 179049
Entertainment 127674
Comedy 87818
Animation 73293
Film 73293
Sports 67329
Gadgets 59817
Games 59817
Blogs 48890
People 48890
统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
思路:
-
先找到观看数最高的20个视频所属类别的所有信息,降序排列
-
把这20条信息中的category分裂出来(列转行),使用炸裂函数
-
最后查询视频分类名称和该分类下有多少个Top20的视频
- 第一步:统计视频观看量的前20
sql-- 1 先统计视频观看的前20
select videoId,views,category from gulivideo_orc order by views desc limit 20;t1
- 对t1表进行炸裂,统计类别信息
sql-- 2 对t1表中的category列进行炸裂操作
select videoId,views,category_name from t1 lateral view explode(category) tmp_category as category_name;t2
select videoId,views,category_name from (select videoId,views,category from gulivideo_orc order by views desc limit 20)t1 lateral view explode(category) tmp_category as category_name;t2
videoid views category_name
dMH0bHeiRNg 42513417 Comedy
0XxI-hvPRRA 20282464 Comedy
1dmVU08zVpA 16087899 Entertainment
RB-wUgnyGv0 15712924 Entertainment
QjA5faZF1A8 15256922 Music
-_CSo1gOd48 13199833 People
-_CSo1gOd48 13199833 Blogs
49IDp76kjPw 11970018 Comedy
tYnn51C3X_w 11823701 Music
pv5zWaTEVkI 11672017 Music
D2kJZOfq7zk 11184051 People
D2kJZOfq7zk 11184051 Blogs
vr3x_RRJdd4 10786529 Entertainment
lsO6D1rwrKc 10334975 Entertainment
5P6UU6m3cqk 10107491 Comedy
8bbTtPL1jRs 9579911 Music
_BuRwH59oAo 9566609 Comedy
aRNzWyD7C9o 8825788 UNA
UMf40daefsI 7533070 Music
ixsZy2425eY 7456875 Entertainment
MNxwAU_xAMk 7066676 Comedy
RUCZJVJ_M8o 6952767 Entertainment
- 对t2表进行分组排序,统计每一类视频个数
sql-- 3 对t2表进行分组求和
select category_name,count(*) as category_count from (select videoId,views,category_name from (select videoId,views,category from gulivideo_orc order by views desc limit 20)t1 lateral view explode(category) tmp_category as category_name)t2 group by category_name order by category_count desc;
category_name category_count
Entertainment 6
Comedy 6
Music 5
People 2
Blogs 2
UNA 1
统计视频观看数Top50所关联视频的所属类别Rank
思路:
- 查询出观看数最多的前50个视频的所有信息(当然包含了每个视频对应的关联视频),记为临时表t1
- 查询视频观看数前50的视频信息
sql-- 统计视频观看数Top5
select relatedId,views from gulivideo_orc order by views desc limit 5;
relatedid views
["OxBtqwlTMJQ","1hX1LxXwdl8","NvVbuVGtGSE","Ft6fC6RI4Ms","plv1e3MvxFw","1VL-ShAEjmg","y8k5QbVz3SE","weRfgj_349Q","_MFpPziLP9o","0M-xqfP1ibo","n4Pr_iCxxGU","UrWnNAMec98","QoREX_TLtZo","I-cm3GF-jX0","doIQXfJvydY","6hD3gGg9jMk","Hfbzju1FluI","vVN_pLl5ngg","3PnoFu027hc","7nrpwEDvusY"] 42513417
["ut5fFyTkKv4","cYmeG712dD0","aDiNeF5dqnA","lNFFR1uwPGo","5Iyw4y6QR14","N1NO0iLbEt0","YtmGrR0tR7E","GZltV9lWQL4","qUDLSsSrrRA","wpQ1llsQ7qo","u9w2z-xtmqY","txVJgU3n72g","M6KcfOAckmw","orkbRVgRys0","HSuSo9hG_RI","3H3kKJLQgPs","46EsU9PmPyk","nn4XzrI1LLk","VTpKh6jFS7M","xH4b9ydgaHk"] 20282464
["x0dzQeq6o5Q","BVvxtb0euBY","Tc4iq0IaPgE","caYdEBT36z0","Wch5akcVofs","FgN4E9-U82s","a0ffAHbxsLY","BaR9j3-radY","jbNCtXtAwUo","XJBfdkDlubU","c6JRE4ZBcuA","nRGZJ8GMg3g","BfR7iz2UqZY","cVHrwiP2vro","CowiFyYfcH4","uYxKs7xXopc","dzYaq2yOCb8","9o_D-M91Hhc","0O04jXoZmgY","XphZDHtt3D0"] 16087899
["RB-wUgnyGv0","Bdgffnf8Hfw","YSLFsov31dA","KDmGXlOJPbQ","Hr-48XYy9Ns","6E1s0LDL-uM","0j3iXi0V3hk","uEXlbUV45pw","KvMsc6OdKWc","9kGIbR7dqyQ","pEu1muGrREA","DolERIvMbzM","gPtR2eSeDIw","3EpF4fRoT4U","Dl2roCEKffM","QERUjf8fbII","9oviIyGYolo","dblCjXdP7bo","IMPGIaXCnaA","TdGgKd4ZyuY"] 15712924
["O9mEKMz2Pvo","Ddn4MGaS3N4","CBgf2ZxIDZk","r2BOApUvFpw","dVUgd8ot6BE","OUi9-jqq_i0","AbndgwfG22k","K3fvB4QO1qo","6rIJJp6aMlA","9wItsn3r_kc","cueXmJDbbvU","Ua3hZXfNZOE","Z2Rl5BsnfdY","pZ9jrBg4Lwc","dt1fB62cGbo","idb2dUtTpuU","j01x2lAFRwk","LmcjAGJOPR0","kFhQM7R4yjM","rNNcMDZn2Qk"] 15256922
- 对相关id进行炸裂操作并且去重
sql-- 2 对relatedid列进行炸裂操作
select relatedId_count from t1 lateral view explode(relatedId) tmp_relatedID as relatedId_count;t2
select relatedId_count from (select relatedId,views from gulivideo_orc order by views desc limit 2)t1 lateral view explode(relatedId) tmp_relatedID as relatedId_count group by relatedId_count;t2
relatedid_count
0M-xqfP1ibo
1VL-ShAEjmg
1hX1LxXwdl8
3H3kKJLQgPs
3PnoFu027hc
46EsU9PmPyk
5Iyw4y6QR14
6hD3gGg9jMk
7nrpwEDvusY
Ft6fC6RI4Ms
GZltV9lWQL4
HSuSo9hG_RI
Hfbzju1FluI
I-cm3GF-jX0
M6KcfOAckmw
N1NO0iLbEt0
NvVbuVGtGSE
OxBtqwlTMJQ
QoREX_TLtZo
UrWnNAMec98
VTpKh6jFS7M
YtmGrR0tR7E
_MFpPziLP9o
aDiNeF5dqnA
cYmeG712dD0
doIQXfJvydY
lNFFR1uwPGo
n4Pr_iCxxGU
nn4XzrI1LLk
orkbRVgRys0
plv1e3MvxFw
qUDLSsSrrRA
txVJgU3n72g
u9w2z-xtmqY
ut5fFyTkKv4
vVN_pLl5ngg
weRfgj_349Q
wpQ1llsQ7qo
- 取出观看数前50的视频所属的类别
sql-- 3 取出观看数前50的视频所属的类别
select category from (select relatedId_count from (select relatedId,views from gulivideo_orc order by views desc limit 2)t1 lateral view explode(relatedId) tmp_relatedID as relatedId_count group by relatedId_count)t2 join gulivideo_orc on t2.relatedId_count == gulivideo_orc.videoId;t3
category
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Film","Animation"]
["Entertainment"]
["Music"]
["Music"]
["Comedy"]
["Music"]
["Comedy"]
["Comedy"]
["Comedy"]
["Music"]
["Music"]
["Comedy"]
["Comedy"]
["Entertainment"]
["Comedy"]
["People","Blogs"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Comedy"]
["Music"]
["Music"]
- 对类别进行炸裂操作
sqlselect explode(category) from t3
select explode(category) from (select category from (select relatedId_count from (select relatedId,views from gulivideo_orc order by views desc limit 2)t1 lateral view explode(relatedId) tmp_relatedID as relatedId_count group by relatedId_count)t2 join gulivideo_orc on t2.relatedId_count == gulivideo_orc.videoId)t3;t4
col
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Film
Animation
Entertainment
Music
Music
Comedy
Music
Comedy
Comedy
Comedy
Music
Music
Comedy
Comedy
Entertainment
Comedy
People
Blogs
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Comedy
Music
Music
Music
Comedy
Comedy
Comedy
Comedy
- 分组求和
sql-- 5 根据类别分组求和
select category_name ,count(*) as category_count from t4 group by category_name order by category_count desc;
select category_name ,count(*) as category_count from (select explode(category)as category_name from (select category from (select relatedId_count from (select relatedId,views from gulivideo_orc order by views desc limit 2)t1 lateral view explode(relatedId) tmp_relatedID as relatedId_count group by relatedId_count)t2 join gulivideo_orc on t2.relatedId_count == gulivideo_orc.videoId)t3)t4 group by category_name order by category_count desc;
category_name category_count
Comedy 28
Music 8
Entertainment 2
People 1
Film 1
Blogs 1
Animation 1
统计每个类别中的视频热度Top10,以Music为例
思路:
-
要想统计Music类别中的视频热度Top10,需要先找到Music类别,那么就需要将category展开,所以可以创建一张表用于存放categoryId展开的数据。
-
向category展开的表中插入数据。
-
统计对应类别(Music)中的视频热度。
创建表
sqlcreate table gulivideo_category(
videoId string,
uploader string,
age int,
categoryId string,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc;
向表中插入数据
sqlinsert into table gulivideo_category
select
videoId,
uploader,
age,
categoryId,-- 类别以字符串形式存储
length,
views,
rate,
ratings,
comments,
relatedId
from
gulivideo_orc lateral view explode(category) catetory as categoryId;
-- 查看表中数据,区别就是类别列从数组形式转换为字符串形式
select * from gulivideo_category limit 10;
gulivideo_category.videoid gulivideo_category.uploader gulivideo_category.age gulivideo_category.categoryid gulivideo_category.length gulivideo_category.views gulivideo_category.rate gulivideo_category.ratings gulivideo_category.commentsgulivideo_category.relatedid
o4x-VW_rCSE HollyW00d81 581 Entertainment 74 3534116 4.48 9538 7756 ["o4x-VW_rCSE","d2FEj5BCmmM","8kOs3J0a2aI","7ump9ir4w-I","w4lMCVUbAyA","cNt29huGNoc","1JVqsS16Hw8","ax58nnnNu2o","CFHDCz3x58M","qq-AALY0DE8","2VHU9CBNTaA","KLzMKnrBVWE","sMXQ8KC4w-Y","igecQ61MPP4","B3scImOTl7U","X1Qg9gQKEzI","7krlgBd8-J8","naKnVbWBwLQ","rmWvPbmbs8U","LMDik7Nc7PE"]
P1OXAQHv09E smosh 434 Comedy 59 3068566 4.55 15530 7919 ["uGiGFQDS7mQ","j1aBQPCZoNE","WsmC6GXMj3I","pjgxSfhgQVE","T8vAZsCNJn8","7taTSPQUUMc","pkCCDp7Uc8c","NfajJLln0Zk","tD-ytSD-A_c","eHt1hQYZa2Y","qP9zpln4JVk","zK7p3o_Mqz4","ji2qlWmhblw","Hyu9HcqTcjE","YJ2W-GnuS0U","NHf2igxB8oo","rNfoeY7F6ig","XXugNPRMg-M","rpIAHWcCJVY","3V2msHD0zAg"]
N0TR0Irx4Y0 Brookers 228 Comedy 140 3836122 3.16 12342 8066 ["N0TR0Irx4Y0","hX21wbRAkx4","OnN9sX_Plvs","ygakq6lAogg","J3Jebemn-jM","bDgGYUA6Fro","aYcIG0Kmjxs","kMYX4JWke34","Cy8hppgAMR0","fzDTn342L3Q","kOq6sFmoUr0","HToQAB2kE3s","uuCr-nXLCRo","KDrJSNIGNDQ","pb13ggOw9CU","nDGRoqfwaIo","F2XZg0ocMPo","AMRBGt2fQGU","sKq0q8JdriI","bHnAETS5ssE"]
seGhTWE98DU vidsquare 619 Music 198 3296342 4.57 13657 8639 ["xd03Xz7U41A","e5eLJIVY2zs","5-uT93fl8aE","OIpslHiXv7U","b9AohUJAJpc","nmyou72bIoA","y7tb8uhHn4w","F7JRcN8x3Ew","k7_i-K5uKSo","tpxJ9rpg5A8","P75-LsO-rNA","Zk8UFNbcysA","RIuaGhrvUFg","3zWi2Ig91_Q","zby0NdFGSPY","DBElvQroZ6I","wx2o5bdRWvg","tAKCSJcBQr4","7KWlOOhShhs","w3z4fuBchpU"]
bNF_P281Uu4 mattharding2718 490 Travel 222 5231539 4.81 29152 12529 ["7WmMcqp670s","RFtTSisZtVY","JFeSH655mas","6FzTEVnwYes","WZYDizqz_Vs","-3TgQyVVAuw","Jd8I5ParUcw","F0L-tYSBw-Y","S-NBv179--s","TjhEebKUVI4","OfP14Nx7504","Esr6EhgWF94","5Dhbw2UWif0","oK00chrYG-I","cwCov7D5NRI","Ji0kcdwE8m4","sLcrB5psfsI","4WCUlSlCl4E","V8DWO-Ox5aU","IekXybapCTo"]
bNF_P281Uu4 mattharding2718 490 Places 222 5231539 4.81 29152 12529 ["7WmMcqp670s","RFtTSisZtVY","JFeSH655mas","6FzTEVnwYes","WZYDizqz_Vs","-3TgQyVVAuw","Jd8I5ParUcw","F0L-tYSBw-Y","S-NBv179--s","TjhEebKUVI4","OfP14Nx7504","Esr6EhgWF94","5Dhbw2UWif0","oK00chrYG-I","cwCov7D5NRI","Ji0kcdwE8m4","sLcrB5psfsI","4WCUlSlCl4E","V8DWO-Ox5aU","IekXybapCTo"]
CQO3K8BcyGM TheHill88 548 Comedy 65 3083875 2.22 36460 15444 ["AX3aSeHwf7A","Kt-kvm_5a7Q","V5m2SzdMcPY","xnPX6FhjJBA","KVwOe8i8z4k","Auo9xiUVLVY","SGg6EHotg3E","uc4u1ZMqU98","rxLf50ZME38","lX403b5o2yw","hwL6QuO7djk","Wt3e27jKKBY","W6-l-Qg-LYw","S7iuckvGDRs","ZngFu4vFW2o","xyzXDKFnWtI","P3VAy9Tqvrk","6bhPfjo4lmI","33ue4RBFc6w","us7FDugkLeA"]
3gg5LOd_Zus NewNuma 570 Entertainment 207 4200257 3.73 35964 17657 ["MC1hVHDz7tw","oMWYrMAmbj8","LsDOIlFxMKU","yoiNmHAJ8GA","Do5OmHsDBd4","9Tzetis50Pg","iW1rW3NhanM","y6Lw8BTqWDM","PHv5d735A3E","kwzgb1Cq2kI","iHw72X6AMDw","ywXKhvhQ2v4","e14SdZSm6aA","4-4Am-xdjqU","-4T7RR7N2XA","K6x6fjR-dZY","18srddtzW4Q","ahrbm2G0N7g","ZZfBnemBats","vLl-2QG3HUs"]
sdUUx5FdySs Madyeti47 497 Film 189 5840839 4.78 42417 17797 ["_JH-KGwUV9M","t5LDRjiBIGA","EDjnYuVnqq4","er6QIKDtn8Y","4fODSPaqCfs","WMN1pPC1mcg","sdUUx5FdySs","SUbryU_XfX0","ko-H5gX5C14","bev149PYFZE","6wwcp0sNd7s","eFsArrSXLZ8","moum7hC8mY8","edxt2BqZErA","hjS5Q0KdHZI","W7qA56yC64A","ZA-hmLAiGos","WPaqSMbTYfk","pODLB84Glvo","O7oHhyIdPmc"]
sdUUx5FdySs Madyeti47 497 Animation 189 5840839 4.78 42417 17797 ["_JH-KGwUV9M","t5LDRjiBIGA","EDjnYuVnqq4","er6QIKDtn8Y","4fODSPaqCfs","WMN1pPC1mcg","sdUUx5FdySs","SUbryU_XfX0","ko-H5gX5C14","bev149PYFZE","6wwcp0sNd7s","eFsArrSXLZ8","moum7hC8mY8","edxt2BqZErA","hjS5Q0KdHZI","W7qA56yC64A","ZA-hmLAiGos","WPaqSMbTYfk","pODLB84Glvo","O7oHhyIdPmc"]
select * from gulivideo_orc limit 10;
gulivideo_orc.videoid gulivideo_orc.uploader gulivideo_orc.age gulivideo_orc.category gulivideo_orc.length gulivideo_orc.views gulivideo_orc.rate gulivideo_orc.ratings gulivideo_orc.comments gulivideo_orc.relatedid
o4x-VW_rCSE HollyW00d81 581 ["Entertainment"] 74 3534116 4.48 9538 7756 ["o4x-VW_rCSE","d2FEj5BCmmM","8kOs3J0a2aI","7ump9ir4w-I","w4lMCVUbAyA","cNt29huGNoc","1JVqsS16Hw8","ax58nnnNu2o","CFHDCz3x58M","qq-AALY0DE8","2VHU9CBNTaA","KLzMKnrBVWE","sMXQ8KC4w-Y","igecQ61MPP4","B3scImOTl7U","X1Qg9gQKEzI","7krlgBd8-J8","naKnVbWBwLQ","rmWvPbmbs8U","LMDik7Nc7PE"]
P1OXAQHv09E smosh 434 ["Comedy"] 59 3068566 4.55 15530 7919 ["uGiGFQDS7mQ","j1aBQPCZoNE","WsmC6GXMj3I","pjgxSfhgQVE","T8vAZsCNJn8","7taTSPQUUMc","pkCCDp7Uc8c","NfajJLln0Zk","tD-ytSD-A_c","eHt1hQYZa2Y","qP9zpln4JVk","zK7p3o_Mqz4","ji2qlWmhblw","Hyu9HcqTcjE","YJ2W-GnuS0U","NHf2igxB8oo","rNfoeY7F6ig","XXugNPRMg-M","rpIAHWcCJVY","3V2msHD0zAg"]
N0TR0Irx4Y0 Brookers 228 ["Comedy"] 140 3836122 3.16 12342 8066 ["N0TR0Irx4Y0","hX21wbRAkx4","OnN9sX_Plvs","ygakq6lAogg","J3Jebemn-jM","bDgGYUA6Fro","aYcIG0Kmjxs","kMYX4JWke34","Cy8hppgAMR0","fzDTn342L3Q","kOq6sFmoUr0","HToQAB2kE3s","uuCr-nXLCRo","KDrJSNIGNDQ","pb13ggOw9CU","nDGRoqfwaIo","F2XZg0ocMPo","AMRBGt2fQGU","sKq0q8JdriI","bHnAETS5ssE"]
seGhTWE98DU vidsquare 619 ["Music"] 198 3296342 4.57 13657 8639 ["xd03Xz7U41A","e5eLJIVY2zs","5-uT93fl8aE","OIpslHiXv7U","b9AohUJAJpc","nmyou72bIoA","y7tb8uhHn4w","F7JRcN8x3Ew","k7_i-K5uKSo","tpxJ9rpg5A8","P75-LsO-rNA","Zk8UFNbcysA","RIuaGhrvUFg","3zWi2Ig91_Q","zby0NdFGSPY","DBElvQroZ6I","wx2o5bdRWvg","tAKCSJcBQr4","7KWlOOhShhs","w3z4fuBchpU"]
bNF_P281Uu4 mattharding2718 490 ["Travel","Places"] 222 5231539 4.81 29152 12529 ["7WmMcqp670s","RFtTSisZtVY","JFeSH655mas","6FzTEVnwYes","WZYDizqz_Vs","-3TgQyVVAuw","Jd8I5ParUcw","F0L-tYSBw-Y","S-NBv179--s","TjhEebKUVI4","OfP14Nx7504","Esr6EhgWF94","5Dhbw2UWif0","oK00chrYG-I","cwCov7D5NRI","Ji0kcdwE8m4","sLcrB5psfsI","4WCUlSlCl4E","V8DWO-Ox5aU","IekXybapCTo"]
CQO3K8BcyGM TheHill88 548 ["Comedy"] 65 3083875 2.22 36460 15444 ["AX3aSeHwf7A","Kt-kvm_5a7Q","V5m2SzdMcPY","xnPX6FhjJBA","KVwOe8i8z4k","Auo9xiUVLVY","SGg6EHotg3E","uc4u1ZMqU98","rxLf50ZME38","lX403b5o2yw","hwL6QuO7djk","Wt3e27jKKBY","W6-l-Qg-LYw","S7iuckvGDRs","ZngFu4vFW2o","xyzXDKFnWtI","P3VAy9Tqvrk","6bhPfjo4lmI","33ue4RBFc6w","us7FDugkLeA"]
3gg5LOd_Zus NewNuma 570 ["Entertainment"] 207 4200257 3.73 35964 17657 ["MC1hVHDz7tw","oMWYrMAmbj8","LsDOIlFxMKU","yoiNmHAJ8GA","Do5OmHsDBd4","9Tzetis50Pg","iW1rW3NhanM","y6Lw8BTqWDM","PHv5d735A3E","kwzgb1Cq2kI","iHw72X6AMDw","ywXKhvhQ2v4","e14SdZSm6aA","4-4Am-xdjqU","-4T7RR7N2XA","K6x6fjR-dZY","18srddtzW4Q","ahrbm2G0N7g","ZZfBnemBats","vLl-2QG3HUs"]
sdUUx5FdySs Madyeti47 497 ["Film","Animation"] 189 5840839 4.78 42417 17797 ["_JH-KGwUV9M","t5LDRjiBIGA","EDjnYuVnqq4","er6QIKDtn8Y","4fODSPaqCfs","WMN1pPC1mcg","sdUUx5FdySs","SUbryU_XfX0","ko-H5gX5C14","bev149PYFZE","6wwcp0sNd7s","eFsArrSXLZ8","moum7hC8mY8","edxt2BqZErA","hjS5Q0KdHZI","W7qA56yC64A","ZA-hmLAiGos","WPaqSMbTYfk","pODLB84Glvo","O7oHhyIdPmc"]
6B26asyGKDo NK5000 558 ["Film","Animation"] 345 5147533 4.58 31792 21957 ["IvDxUoadG6A","J_gQNniBZ6w","DnVtoifKFzo","-V8QkoY5YUI","tavoL4x2F0o","sFc23gkmgT0","8GWsVHnX54o","qopyzZyjiXI","zujnU9nH3sU","t6K9f58XBuk","BENmbHnv9MM","0ekrC9zUg0I","G50ExTLOAQc","UkjDX8KJ2tg","KkWQqzQOFcs","6e8Niisn9Xg","axm3cP_ob6g","txIqH4Tawuk","iTMINnuszrQ","l7YFFQC3tS4"]
ihhEp3uTZck JoshFlowers 715 ["People","Blogs"] 185 533936 4.16 2948 2133 ["ihhEp3uTZck","OvlnbDIqS2k","qlC-I74mZmo","TkCTYIJW1fY","vMtil93-ZeM","goWDIWlrjeo","i3IS-uxiezc","pqDZfCRJKJY","-RQcKaXQCLk","x8SbjDwxQmQ","lLlLnVGsEHc","4JBQ-02aGQ4","g1Oz9llnYZc","b-n_0yIfE28","px-9jsy4wts","dWnDd_uVzJ8","RmbsgmUq8M0","bi0MkR7eoZQ","gyQFT8QqqU0","1fr0nqc-Ihs"]
统计Music类别的Top10(也可以统计其他)
sqlselect
videoId,
views
from
gulivideo_category
where
categoryId = "Music"
order by
views
desc limit
10;
-- 如果这样做的话需要统计多次,浪费时间
videoid views ratings
QjA5faZF1A8 15256922 120506
pv5zWaTEVkI 11672017 42386
UMf40daefsI 7533070 31886
tYnn51C3X_w 11823701 29479
59ZX5qdIEB0 1814798 21481
FLn45-7Pn2Y 3604114 21249
-xEzGIuY7kw 6946033 20828
HSoVKUVOnfQ 6193057 19803
ARHyRI9_NB4 1237802 19243
gg5_mlQOsUQ 2595278 19190
使用窗口函数统计
sql--统计每个类别中的视频热度Top10
-- 1 给每一种类别根据视频观看数添加rank()值,倒叙
select categoryId,videoId,views,rank() over(partition by categoryId order by views desc) rk from gulivideo_category;t1
-- 2 过滤前十
select categoryId,videoId,views from t1 where rk<=10;
select categoryId,videoId,views from (select categoryId,videoId,views,rank() over(partition by categoryId order by views desc) rk from gulivideo_category)t1 where rk<=10;
统计每个类别中视频流量Top10,以Music为例
思路:
-
创建视频类别展开表(categoryId列转行后的表)
-
按照ratings排序即可
传统写法
sqlselect
videoId,
views,
ratings
from
gulivideo_category
where
categoryId = "Music"
order by
ratings
desc limit
10;
使用窗口函数
- 首先给每一种类别的视频根据流量值添加rank(),按照倒序排序
sql-- 1 首先给每一种类别的视频根据流量值添加rank(),按照倒序排序
select categoryId,videoId,ratings,rank() over(partition by categoryId order by ratings desc) cr from gulivideo_category;t1
categoryid videoid ratings cr
Animals 2GWPOPSXGYI 12086 1
Animals xmsV9R8FsDA 11918 2
Animals AgEmZ39EtFk 9509 3
Animals 12PsUW-8ge4 7856 4
Animals Sg9x5mUjbH8 7720 5
- 统计每一个种类中流量前十的视频
sql--2 统计每一个种类中流量前十的视频
select categoryId,videoId,ratings from t1 where cr<=10;
select categoryId,videoId,ratings from (select categoryId,videoId,ratings,rank() over(partition by categoryId order by ratings desc) cr from gulivideo_category)t1 where cr<=10;
categoryid videoid ratings
Animals 2GWPOPSXGYI 12086
Animals xmsV9R8FsDA 11918
Animals AgEmZ39EtFk 9509
Animals 12PsUW-8ge4 7856
Animals Sg9x5mUjbH8 7720
Animals a-gW3RbJd8U 6888
Animals d9QwK5EHSmg 6598
Animals QmroaYVD_so 6554
Animals OeNggIGSKH8 5921
Animals l9l19D2sIHI 5808
Animation sdUUx5FdySs 42417
Animation 6B26asyGKDo 31792
Animation JzqumbhfxRo 27545
Animation h7svw0m-wO0 27372
Animation AJzU3NjDikY 22973
Animation PnCVZozHTG8 14309
Animation hquCf-sS2sU 13377
Animation o9698TqtY4A 12457
Animation EBcoo8i33L0 12376
Animation 55YYaJIrmzo 10859
Autos RjrEQaG5jPM 5034
Autos 46LQd9dXFRU 3852
Autos cv157ZIInUk 2850
Autos 8c1GGgXLepY 2487
统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
- 先找到上传视频最多的10个用户的用户信息
sql-- 1 统计上传视频数量最多的用户,取前十名
select uploader,videos from gulivideo_user_orc order by videos desc limit 10;
uploader videos
expertvillage 86228
TourFactory 49078
myHotelVideo 33506
AlexanderRodchenko 24315
VHTStudios 20230
ephemeral8 19498
HSN 15371
rattanakorn 12637
Ruchaneewan 10059
futifu 9668
- 通过uploader字段与gulivideo_orc表进行join,得到的信息按照views观看次数进行排序即可。
sql-- 2 取出这10个人上传的所有视频,并且按照观看次数进行排序
select gulivideo_orc.videoId,gulivideo_orc.views from (select uploader,videos from gulivideo_user_orc order by videos desc limit 10)t1 join gulivideo_orc on t1.uploader == gulivideo_orc.uploader order by gulivideo_orc.views desc limit 10;
gulivideo_orc.videoid gulivideo_orc.views
-IxHBW0YpZw 39059
BU-fT5XI_8I 29975
ADOcaBYbMl0 26270
yAqsULIDJFE 25511
vcm-t0TJXNg 25366
0KYGFawp14c 24659
j4DpuPvMLF4 22593
Msu4lZb2oeQ 18822
ZHZVj44rpjE 16304
foATQY3wovI 13576
统计每个类别视频观看数Top10
思路:
-
先得到categoryId展开的表数据
-
子查询按照categoryId进行分区,然后分区内排序,并生成递增数字,该递增数字这一列起名为rank列
-
通过子查询产生的临时表,查询rank值小于等于10的数据行即可。
sqlselect
t1.*
from (
select
videoId,
categoryId,
views,
row_number() over(partition by categoryId order by views desc) rank from gulivideo_category) t1
where
rank <= 10;
本文作者:csn
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!